OpenAI Codex: 如何打造一个 AI Native 工程团队

🥥
TL;DR
-
AI Coding 工具的主战场正在从“帮工程师更快写代码”转向“帮助团队重新组织软件交付流程”。
-
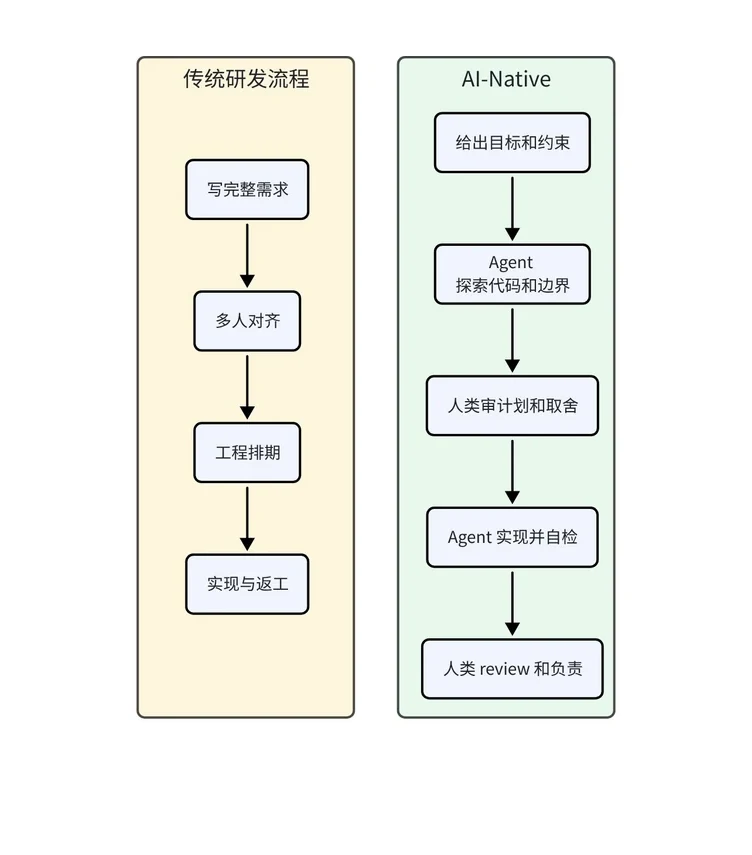
过去我们把 AI Coding 理解成自动补全、生成函数、解释代码、修 bug。现在 Codex 团队展示的是另一种范式:
- 人类把一段完整工作委派给 Agent,让 Agent 搜代码、拟计划、改实现、跑检查、写总结;
- 人类则负责方向、约束、判断、审查和最终责任。
Reference

从产出代码到管理委派
OpenAI Codex Team 对 Build 阶段有一句很关键的洞察:“The agent becomes the first-pass implementer”
这背后是分工变化:Agent 负责第一版实现,人类负责定义方向、判断正确性、审查质量和承担最终责任。
过去大量依赖长文档传递的上下文,现在可以通过 agent 直接探索代码库、生成方案、提出歧义点和快速原型来补齐。
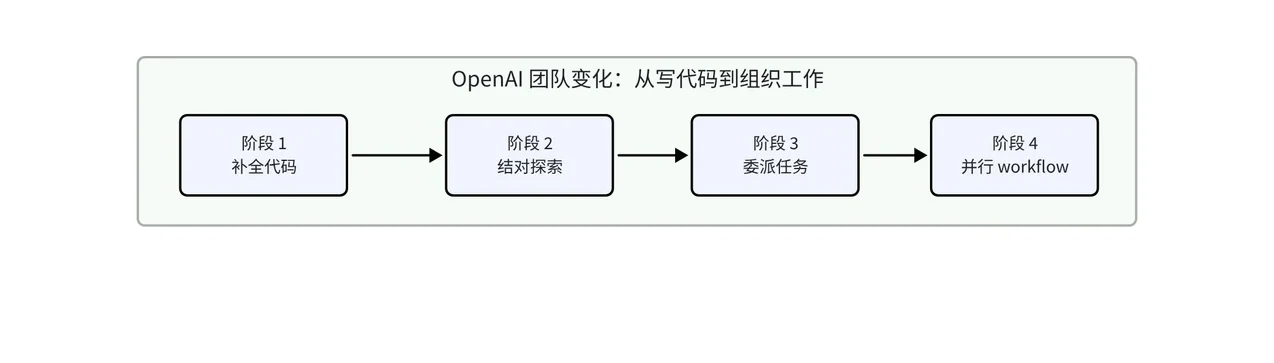
Codex 团队给出的组织信号
少写长 Spec
Codex 团队只在问题复杂到跨多人协调,或者决策很棘手时写 spec。即使写,也通常很短。
这背后的假设是:
- 代码库上下文可以由 Agent 快速读取。
- 实现路径可以通过 Plan Mode 或探索性任务暴露。
- 很多细节可以在原型和 diff 中讨论,不必提前写进长文档。
- 人类注意力应该放在关键判断上,而非搬运上下文。
不迷信中期 Roadmap
OpenAI 内部的一个判断:要么规划非常近的具体目标,要么保持长期方向感;中间那种精确的中期路线图容易失真。
这对快速变化的 AI 产品尤其明显。模型能力、用户行为、工具边界都在变化,团队更需要短周期执行和长期方向感,而不是把不确定性包装成确定排期。
Codex App 的本质是多 Agent 委派界面
Codex App 并非是简单替代 CLI 或 IDE extension。它的核心意义是让“同时委派多个 agent 工作”变得自然。
过去高级用户会开多个 Terminal、多个 Worktree、多个任务并行跑。Codex App 试图把这种高级工作流产品化:让普通用户也能理解、切换、审查多个 agent 的工作。
OpenAI Guide 的 SDLC 框架
OpenAI guide 把 AI-native engineering 拆成 7 个阶段。这个框架适合团队内部用来检查:哪些环节已经可以委派,哪些环节仍然必须人类负责。
| 阶段 | Agent 可以委派什么 | 人类主要负责什么 | 风险点 |
|---|---|---|---|
| Plan | 读需求、查代码、拆任务、暴露歧义 | 优先级、范围、取舍 | 模糊需求被过早实现 |
| Design | 原型、组件初版、设计系统映射 | 体验质量、交互判断 | 只还原 UI,不理解体验 |
| Build | first-pass 实现、改多文件、修构建错误 | 架构、业务逻辑、长期质量 | 代码变多但系统变乱 |
| Test | 生成用例、补边界、维护测试 | 判断测试是否验证真实行为 | 伪测试、空测试 |
| Review | 初步找 bug、硬编码、竞态、跨文件问题 | 最终 review 和 merge | 低信噪比意见淹没重点 |
| Document | 生成说明、图、release summary | 组织结构、关键背景、why | 文档正确但没有洞察 |
| Deploy | 查日志、看 git history、辅助定位 incident | 生产判断、修复方案、风险控制 | 误判根因或权限过大 |
最重要的工作模型:Delegate / Review / Own
AI-native 团队把工作拆成三层,而非把责任交给 AI。
| 层次 | 适合交给谁 | 典型任务 | 判断标准 |
|---|---|---|---|
| Delegate | Agent | 搜代码、拆任务、生成初版、补测试、写总结 | 可描述、可验证、失败成本可控 |
| Review | 人类主导,Agent 辅助 | PR review、测试审查、架构影响分析 | 输出是否正确、完整、可维护 |
| Own | 人类 owner | 产品方向、架构取舍、生产发布、团队标准 | 谁最终负责结果 |
这个模型比“AI 能不能替代工程师”更有用。它把问题从身份讨论,转成工作分解。
角色边界正在变化
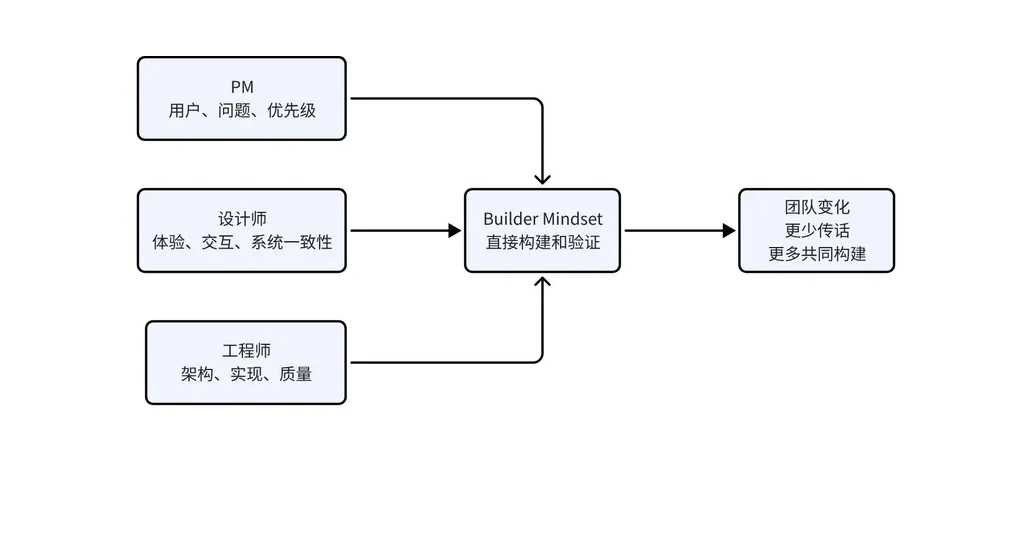
PM、设计师、工程师都在更靠近“构建”。
设计师可以用 Codex 把设计稿和组件规范变成可运行原型。
PM 可以让 Codex 汇总反馈、理解代码、拆任务,甚至提交小 PR。
工程师可以更快探索用户问题、验证多个方案。
这种变化并非让所有人都转化为同一种角色,其本质在于 Agent 扩展了每个角色的能力半径。
| 角色 | 过去常见输出 | AI-native 后的新增能力 | 不应丢掉的核心责任 |
|---|---|---|---|
| PM | 需求、排期、协调 | 代码理解、反馈归纳、任务拆分、小 PR | 用户理解、方向判断、优先级 |
| 设计师 | 静态稿、交互说明 | 高保真原型、组件实现、可运行体验验证 | 体验质量、设计系统、可访问性 |
| 工程师 | 代码实现、修 bug | 多 agent 委派、快速探索、跨域实现 | 架构、正确性、可维护性 |
| Tech Lead | 分工、review、方案 | 设计 guardrails、让 agent 稳定复用团队规范 | 系统一致性、工程标准、风险控制 |
设计师的变化:从静态交付到可运行体验
如果只把 AI-native 理解成“工程师写代码更快”,会漏掉一个很重要的变化:设计师的工作边界正在明显外扩。
Codex 团队内部的变化:设计师现在写的代码比六个月前一个工程师写的还要多。
这句话容易被误读成“设计师要变成工程师”。更准确的理解是:agent 让设计师获得了低成本表达动态体验的能力。过去设计师主要交付静态稿、交互说明、状态标注;现在可以更早把体验跑起来,用可交互原型、组件初版和真实状态流来讨论产品。
OpenAI 指南在设计阶段也给出了类似的判断:coding agents 能够显著加速原型开发和基础代码的搭建。它们可以自动应用 design tokens 和 style guides,生成 component stubs,并直接将设计稿转化为代码。
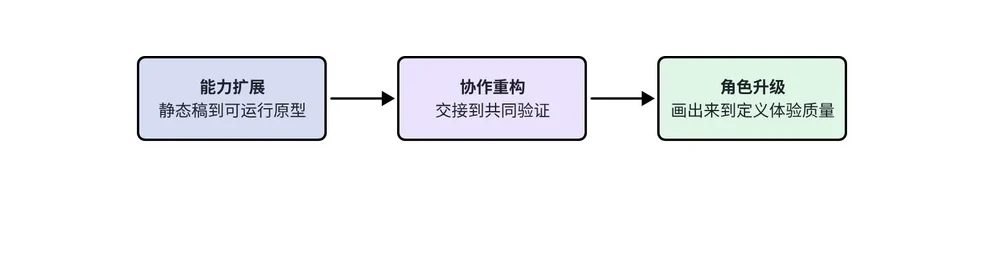
能力扩展:设计师拥有动态表达能力
设计师过去经常受限于表达媒介。Figma 可以表达视觉和部分交互,但很多体验问题只有跑起来才会暴露,例如:
- 加载、空状态、错误状态是否自然。
- 多步骤流程是否顺畅。
- 组件在真实数据下是否失衡。
- 微交互和动效节奏是否合适。
- 设计系统在真实代码中是否能一致落地。
AI-native 后,设计师可以把 agent 当作“原型实现助手”:根据设计稿、组件库、design token、自然语言描述,快速生成一个可运行版本。这个版本不一定能直接进生产,但足够用于体验验证和协作讨论。
| 设计任务 | 过去常见方式 | AI-native 后的变化 |
|---|---|---|
| 表达交互 | 静态稿 + 文字说明 | 可运行 demo 直接体验 |
| 验证状态 | 标注若干状态页 | 让 agent 补全状态流 |
| 多方案探索 | 成本高,只能少量尝试 | 快速生成多个可试版本 |
| 设计系统落地 | 依赖工程师理解和还原 | agent 读取组件库和 token 后实现初版 |
协作重构:从设计交接到共同验证
当设计师可以更早拿出可运行体验,设计和工程的关系会从“上游交付、下游实现”变成“共同验证”。
工程师的作用反而愈发关键了。他们现在会更早地参与到架构设计、系统性能、可维护性以及各种技术约束的讨论中;与此同时,设计师也提前介入了真实交互的处理、状态完整性的构建以及具体的体验细节。
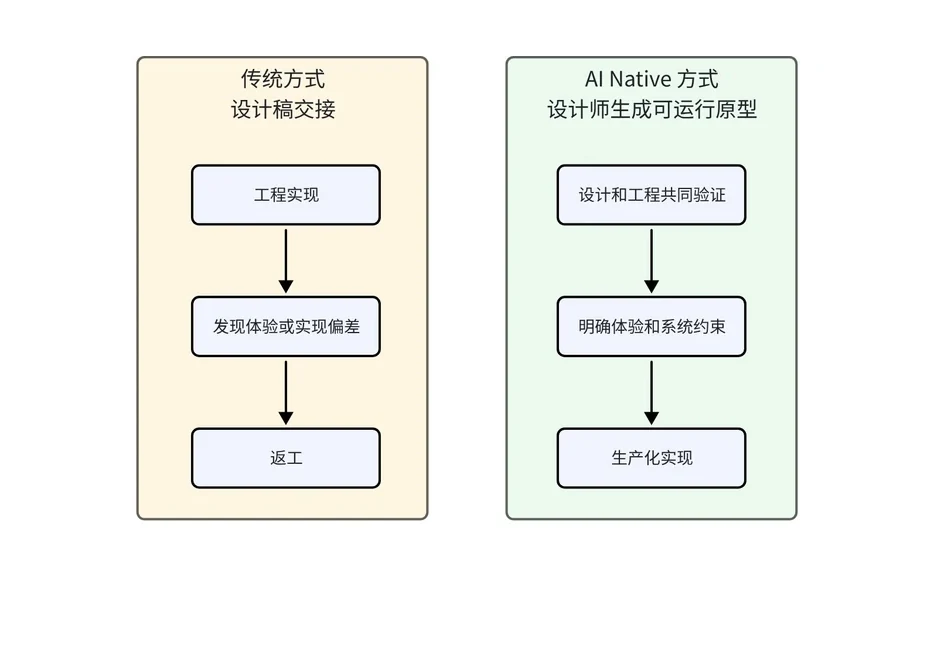
对团队来说,评审的重点正发生本质变化,不再是对着静态视觉稿指指点点,而是直接上手体验真实的产品操作。大家的讨论中心也从过去纠结“技术能不能实现”变成了权衡“哪些体验才真正值得投入量产”。
现在的设计与工程也不再是机械的还原关系,而是双方坐在一起共同探讨并最终确定交付边界。
角色升级:设计师更聚焦体验判断
当实现初版的成本下降时,设计师的价值并不会随之降低,反而会更加集中在那些难以被替代的核心能力上。
这种价值体现在能否确保用户路径符合真实意图、信息架构是否有效降低了认知负担,以及交互反馈是否做到了及时、清楚且克制。
同时,设计师还需要考量设计系统的一致性与可扩展性,并在多方案探索后,能够清晰阐述选择特定方向的理由。
更关键的是,设计师必须敏锐地判断出哪些体验细节是需要绝对坚持的,而哪些部分则是可以为了大局做出让步的。
✏️
AI-native 的核心逻辑在于赋予设计师低成本的动态表达手段,让他们能跳出静态图纸的限制,直接在可运行的真实体验中进行验证。 这并不意味着设计师要跨行去抢工程师的饭碗,相反,设计师的角色将迎来一次重要的升级:从单纯的稿件产出者,转变为产品体验质量的定义者与守护者。
对团队的启发
通用团队可以先从几个轻量的实践入手,让协作更自然。
比如重要体验别只看静态稿,尽量补个可运行的原型;设计评审时也要多留个心眼,把加载、空状态、报错、权限和边界数据这些状态都过一遍。
设计师现在可以尝试用 Agent 读取组件库来生成组件级 Demo,而工程师也别干等着设计交付,早点介入去定义系统约束和生产边界会更高效。
最后,PM、设计和工程团队最好都聚在可运行的原型前讨论,这样比凭空想象实现方案要靠谱得多。
对团队的通用启发
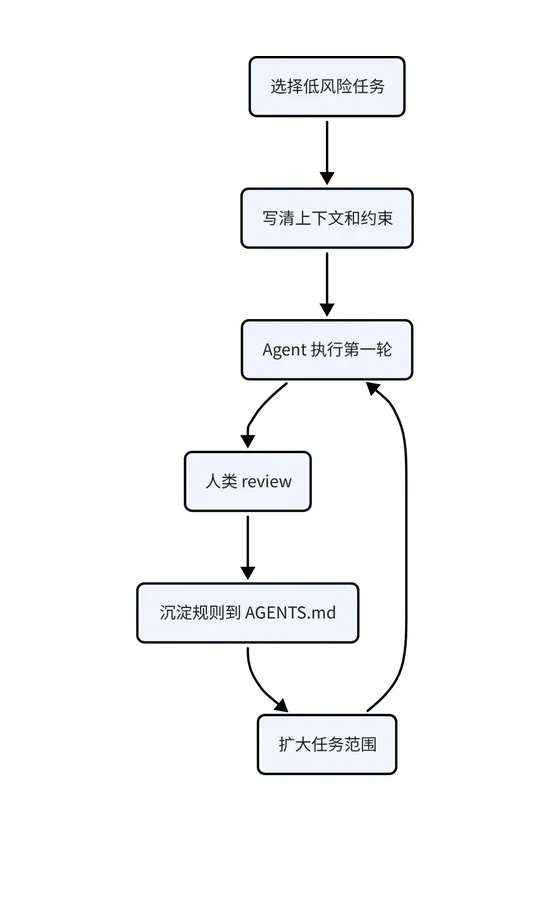
从小场景开始,而不是直接重构流程
建议给团队引入 AI 启发时不要急着直接重构现有流程,尤其是没必要一上来就追求所谓的“全流程 AI-native”,从小场景切入其实更稳妥。我们可以先从那些风险低、重复性高且容易验证的地方做起,比如在需求进入开发前,先让 Agent 帮忙查查代码、定位相关模块,或者列出潜在的风险和歧义。在具体执行上,可以让 AI 负责小型任务的初步实现,人来把控 Review 质量;测试方面则可以交给它去分析边界场景并生成用例。此外,像 PR 的初审、同步更新文档和 Release Note,以及结合日志和 Git 记录进行故障初步定位,都是非常自然且高效的应用场景,由工程师最后把关即可。这样循序渐进地把 AI 嵌入到现有工作流中,效果会比强行重构好得多。
不建议一开始就追求“全流程 AI-native”。更适合从低风险、高重复、可验证的场景开始:
- 需求进入开发前:让 agent 查代码、找相关模块、列风险和歧义点。
- 小型实现任务:让 agent 做 first-pass implementation,人类重点 review。
- 测试补充:让 agent 分析边界场景并生成测试,再由工程师审查。
- PR 初审:让 AI 先找 bug、遗漏、硬编码和跨文件风险。
- 文档更新:把 PR summary、模块说明、release note 纳入交付流程。
- 故障排查:让 agent 结合日志、部署记录和 git history 做初步定位。
先建设护栏,再扩大委派范围
Agent 的质量高度依赖于团队提供的上下文和约束,因此团队需要通过维护 AGENTS.md 来明确项目结构、命令、测试方式、代码规范及禁止事项,并建立有效的 Feedback loop,确保 Agent 能够运行诸如构建、静态检查、测试和类型检查等真实命令。
同时,应为 Agent 设定明确的评审标准,涵盖测试、架构、安全和生产风险等方面,在流程上坚持从小任务开始积累信任并逐步过渡到复杂任务,并严格执行“谁合并代码,谁对结果负责”的原则。
团队规范会被放大
规范清楚,agent 会复用规范;规范混乱,agent 会复制混乱。
AI-native 的前置工作并非工具,核心在于将团队的隐性知识显性化:
- “正确的项目命令是什么?”
- “什么样的测试才算有效?”
- “哪些目录不能随便改?”
- “PR 描述应该包含哪些信息?”
- “哪些变更必须找 owner review?”
- “哪些生产操作 agent 只能分析,不能执行?”
需要警惕的误区
| 误区 | 为什么危险 | 更好的做法 |
|---|---|---|
| 把 AI-native 等同于更快写代码 | 会制造更多未经设计的代码 | 关注工作分工和验证闭环 |
| 让 agent 处理模糊需求 | 模糊会被快速固化成错误实现 | 先让 agent 暴露歧义,再由人类决策 |
| 相信生成测试天然可靠 | 容易出现伪测试和只测实现细节 | 人类审查测试是否验证真实行为 |
| AI review 越多越好 | 低信噪比会被团队忽略 | 聚焦 P0/P1、跨文件逻辑和生产风险 |
| 忽略权限和安全边界 | Agent 可能访问或操作过多系统 | 明确 access scope 和操作权限 |
结论
Codex 团队展现了超前的工作模式:少写长 spec、少做中期路线图、更多依赖快速探索和多 agent 委派。OpenAI 的指南进一步将这些实践升华为一套完整的软件生命周期方法论。
从这些经验中可以看出,AI 原生工程的本质在于重新定义分工。团队通过将机械的实现工作交给 Agent,把更多精力提前投入到探索和验证中,从而让成员能专注于决策、架构设计、质量把控及责任分配。
这种模式让团队告别了传统的串行交付,转向更高效的并行协作。
👩🎨
真正值得团队沉淀的是建立一套全新的工作直觉和协作习惯: 凡是可以被清晰描述、可以被工具验证、失败成本可控的工作,都应该优先尝试委派给 agent 凡是涉及方向、责任、长期质量和生产风险的判断,都必须由人类 owner 承担。