删掉你的 AGENTS.md:它很可能在给你的 Coding Agent 帮倒忙
TL;DR
不要自动生成那种“仓库说明书式”的
AGENTS.md / CLAUDE.md。它会占用上下文预算,还可能把过期信息变成高权重前提。
AGENTS.md要尽可能精简,只写两类东西:
Coding Agent 无法(或很难)从代码里推导出来的事实。
你在使用 Agent 开发过程中总结出来的纠偏指引。
如果你在仓库里/模块里放了 AGENTS.md / CLAUDE.md 等上下文工程的记忆文件,也许你该做一件反直觉的事:先把它删掉。
不是因为“规则文件没用”。而是因为很多团队写出来的那一份,尤其是自动生成的长文档,常常在让 Coding Agent 更慢、更贵,还更容易走偏。
在 2025 年流行的上下文工程实践里,AGENTS.md / CLAUDE.md 经常被提及,很多实践分享往往建议通过
/init等命令一键生成仓库级别的 CLAUDE.md 或者通过 Skill 来给 monorepo 的某个模块一键生成模块级别的 CLAUDE.md。
然而模型能力进步一日千里,在 2026 年 3 月当下这个时间节点,一键自动生成的记忆文件可能反而是个累赘。
我说“删掉”,指的是哪种 AGENTS.md
不是让你永远不写。我更想删掉的是这一类:
-
一键自动生成的仓库说明书
-
带大量目录枚举、脚本列表、泛化风格约定
-
写得很像事实,但其实没人维护
这类文件很容易成为高权重噪声。
当它存在时,agent 会把它当成工作前提。
你得到的不是“更懂你的项目”,而是“更坚决地遵守一份可能不准确的说明”。
上下文工程的第一条常识:上下文窗口是稀缺资源
上下文窗口不是无限的。你把一段长 rules 放进去,等价于从同一个窗口里挤走别的内容。
通常被挤走的才是更关键的东西:
-
错误栈、日志、实际报错
-
关键函数、接口定义
-
刚刚补充的需求和边界条件
这会改变 agent 的决策顺序。
它更容易在“概览与约定”里兜圈子。也更容易错过局部证据。
自动生成的 AGENTS.md 往往动辄上千行(甚至大几千上万行都见过),挤占了宝贵的上下文窗口,让模型难以将注意力聚焦在任务上,性能下降。
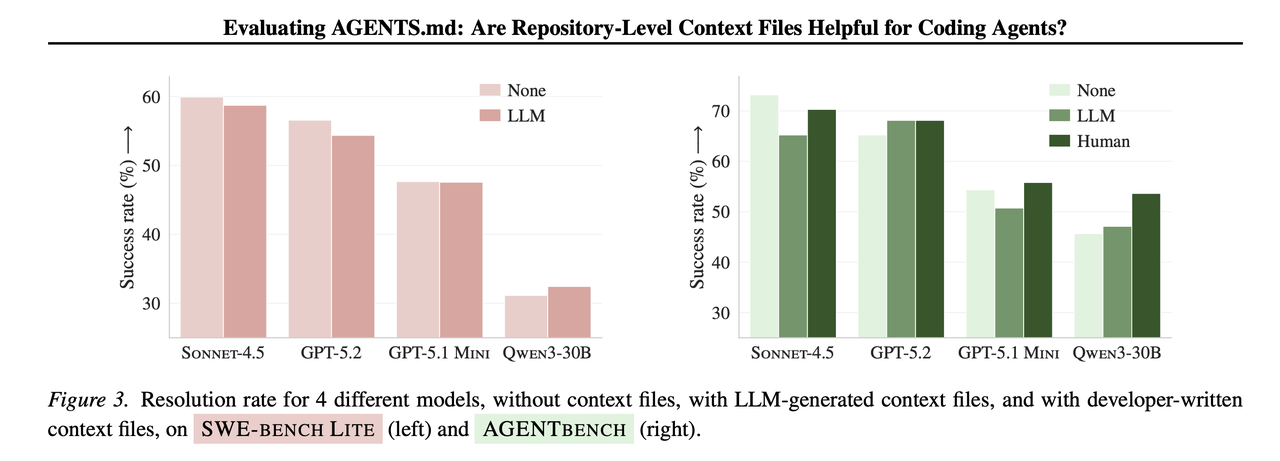
研究里已经看到类似现象:在一些基准和真实 issue 场景下,额外提供仓库级 context file,任务成功率反而下降,推理成本上升(论文给出的整体描述是成本上升 20%+)。
Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?
但这张图能帮你直观看到对照趋势:同一类任务,在“无文件 / 自动生成 / 人写文件”之间,成功率是会波动甚至走低的。
长规则文件的第二个问题:信息密度不够,噪声会反复收费
自动生成的规则文件常见写法很像这样:
-
把
package.json里每条脚本都解释一遍 -
把目录结构从根到叶子列出来
-
把 README 里已有的段落改写一遍
这些信息看起来“全面”,洋洋洒洒上千行。
但你真在修一个具体 bug、改一个边界条件时,它们的边际价值很低。
噪声不是一次性成本。它在每一次推理中都要占 token、占注意力。
论文里有一个很实用的观察:加入 context file 后,平均 steps 增加,成本上升是稳定出现的。
你在实际使用里也很容易体感到这点:同一个需求,agent 变得更“忙”,命令更多、读写更多,但合入更慢。
更危险的点:它会制造“虚假的确定性”
写得像真的内容,会让模型更少去验证。它会把文档当成事实,而不是待证伪的假设。

结果就是:
-
少看代码
-
少跑最关键的最小复现
-
更快给出看似合理的方案
这类错误并不总是立刻爆炸。
它可能在 review、上线前测试、或者线上回滚时才暴露。
回头查原因,经常很难定位到那段规则文字。
规则文件被误用的根源:把它当知识库
很多工程团队的直觉是:“既然 agent 不懂项目,那我把项目知识写进去。”
这句话只对一半。项目知识里有两类:
-
稳定不变量:工具链、命令入口、硬约束、不能踩的线
-
易变细节:目录职责、架构演进、某库是否使用、模式推荐
麻烦在于,大家往往把易变细节写得最多。
维护跟不上时,它很快变成“高权重过期信息”。
而高权重的过期信息,比缺失信息更糟。
证据:为什么“更努力”不等于“更有效”
你可能会说:那我写清楚一点,让 agent 多跑测试、多探索,不是更靠谱吗?
论文的 trace 分析很有解释力。它观察到一件不那么舒服的事:
context file 的确会让 agent 更频繁地测试、grep、读文件、写文件。指令也通常会被遵守。
但这些行为增加了成本,并不稳定地转化成更高成功率。
下面这张图能看到工具调用层面的变化。它不是“某个模型的怪癖”,而是跨设置的共同趋势。
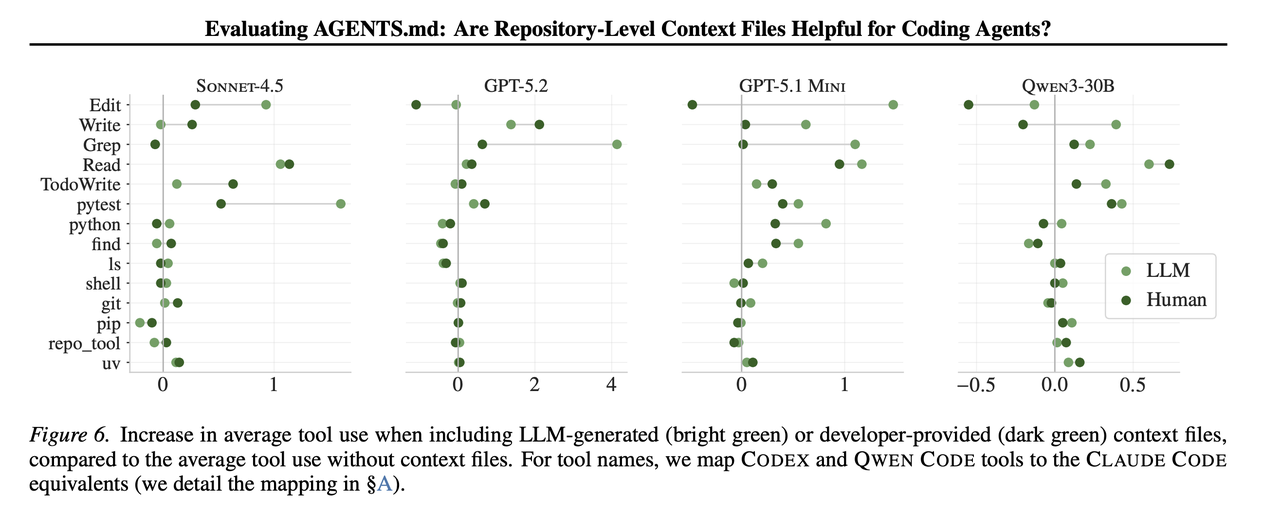
所以问题更像是:你给了额外要求,agent 认真执行了额外要求。任务就变得更长、更难、更贵。
“仓库概览”这件事,很多时候没有带来你期待的收益
不少 AGENTS.md 会专门写一节“项目结构概览”。
直觉上,它应该帮助 agent 更快找到关键文件。
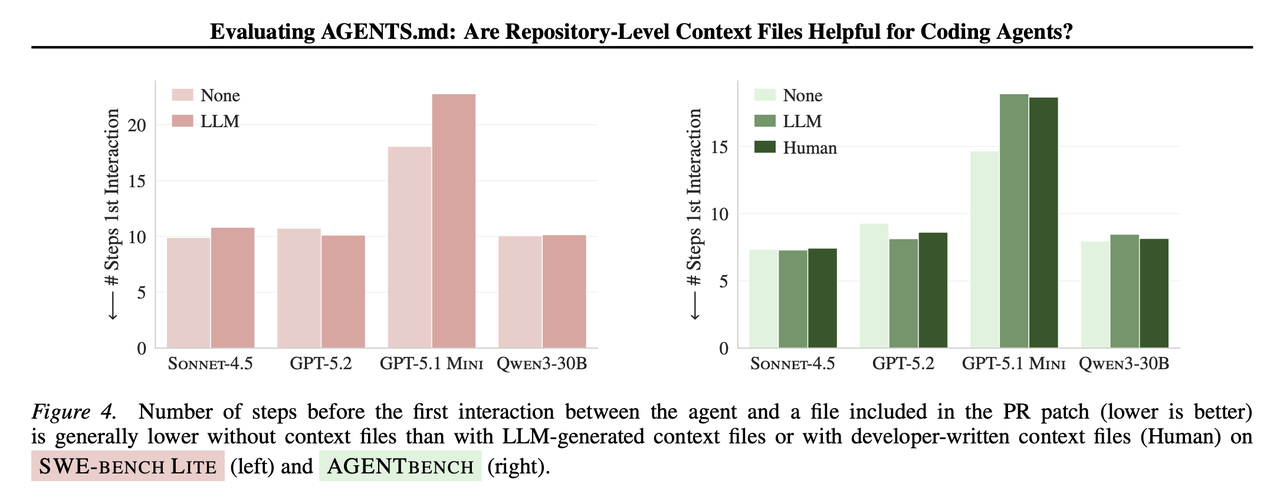
论文用一个指标去验证:在解决任务的过程中,agent 需要多少步才首次触达“原始 PR 修改过的文件”。

结论并不乐观:加入 context file 并没有明显降低这个数字。
两张图放在一起看更清楚。如果你写概览只是为了“让它更快定位”,这两张图值得你停一下。
更合适的写法:把 AGENTS.md 写成“纠偏用的最小约束”
如果你用的是 Claude Code 这类主流 Coding Agent,你大概率已经见过这种流程:
它会读文件、搜索、跑命令、不断迭代。
这时,一份好的 AGENTS.md/CLAUDE.md 不该试图“教会它整个仓库”。
更现实的目标是:
-
限制明显不合规的行为
-
告诉它必须遵守的操作方式
-
提供它从代码里很难推断出来的信息
写作上我会坚持三个原则:短、硬、可验证。
AGENTS.md 应当尽可能简短,能在十几二十行内解决就不要写上百行
具体到内容,我建议只保留三类。
运行方式(How to run)
把命令写清楚。哪怕只有几行也行。关键是能让人和 agent 都照着跑。
写“使用某某工具链”不够。
把 install / test / lint / build 这些最常用的入口写出来,价值就很高。
硬约束(Hard constraints)
硬约束的特点是“违反会出事”。
例子很常见:
-
不要改 public API
-
需要兼容某版本
-
迁移必须带 migration
-
不允许关闭安全检查
这些内容写进文件是合理的。它能直接减少不合规改动。
锐利的坑(Sharp pitfalls)
这类信息通常不会写在代码里。
你们踩过一次就知道它有多浪费时间。
建议写得具体一点:触发条件、后果。
不要写泛泛的“注意性能”。
写“某目录不要引入某依赖,会触发 bundle 体积限制”会更有用。
用实验结束争论
如果团队里对“要不要写 AGENTS.md”争论很久,我更建议做一个小实验。
取十来个真实 ticket。把自动生成的长文档关掉一周。只保留一份极简文件。
对比三件事:
-
成本有没有明显变化(steps、调用量、时间)
-
首次可运行的 patch 比例有没有变化
-
review 返工与幻觉 API 有无变化
这类实验不需要很严谨。它足够让团队从信念回到事实。
收尾:把“删掉”变成一个可执行动作
把自动生成的 AGENTS.md/CLAUDE.md 先移走。
让 agent 在真实任务里跑几次。观察它到底缺什么。
然后再写回一份短文件,只写那些“它从代码里拿不到、但你必须让它遵守”的信息。
这件事做完,你对上下文工程的理解会更具体。
也更容易写出真的有用的规则文件。