《SWE-CI: 用CI评估Agent维护代码库的能力》论文解读:为什么 Claude Opus 4.6 只领先几分,真实体验却像领先一代?
在编程模型的讨论里,一个非常常见、也非常让人困惑的现象是:
很多榜单上,第一名模型和后面几名模型的差距,看起来往往只有 2% 到 5%。比如一个模型 55 分,另一个模型 57 分,表面上似乎只是“更强一点”,远谈不上代际差异。
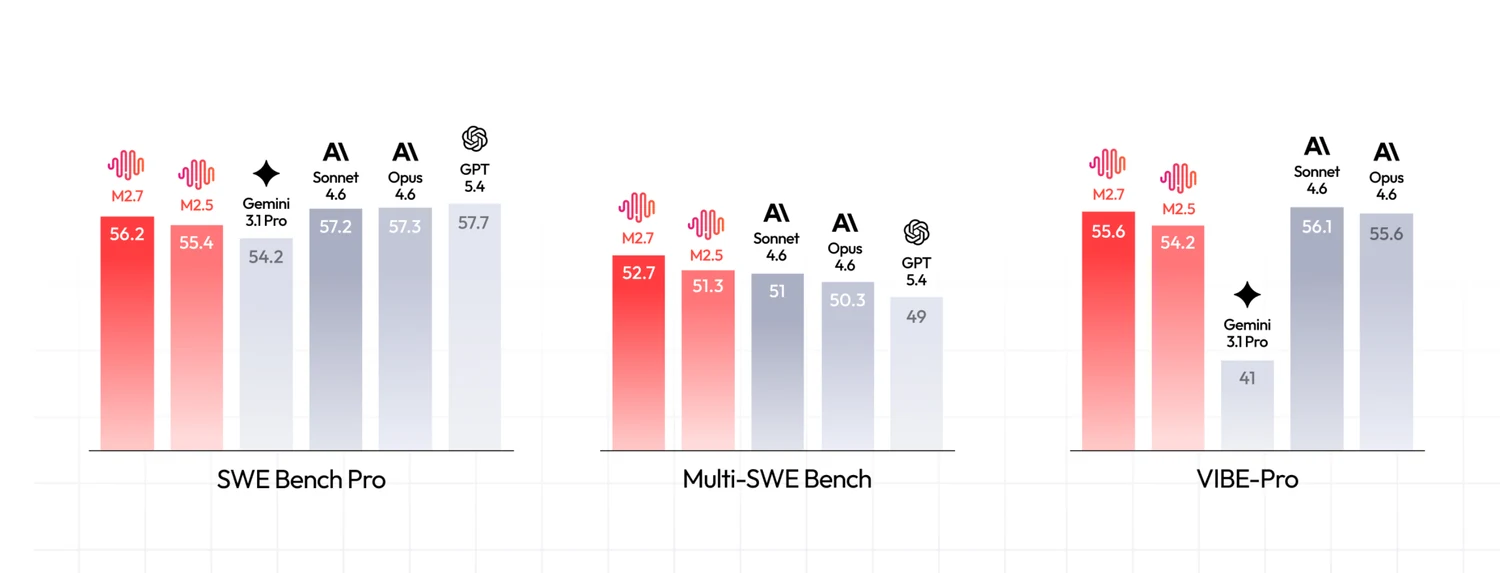
但只要真正把这些模型放进持续性的真实开发任务里,很多人的体感都会迅速变得非常鲜明:这并不是“80 分和 75 分”的区别,而更像是“一个基本能用,一个基本不能用”的区别。
如果要问,为什么排行榜上的差距看起来不大,真实体验却常常差得这么夸张,那么最近这篇论文 SWE-CI,其实提供了一个相当有解释力的答案。
它真正重要的地方,不只是又提出了一个新的 coding benchmark,而是把一个过去常常被忽略、但在真实软件工程里极其关键的问题正式提了出来:
我们到底是在评估模型“会不会一次把代码改对”,还是在评估它“能不能在持续演化中把代码库维护好”?
而这两件事,远不是一回事。
一、很多编程榜单,测的其实是“单次解题能力”
过去几年里,大多数编程 benchmark 的基本范式,都可以概括为一种 snapshot-based evaluation。
也就是说,评测流程通常是这样的:
- 给模型一个静态代码快照
- 给它一个静态任务描述
- 看它能否在这一轮里生成正确 patch
- 最后用测试是否通过来判断成败
这种评测方式当然有价值。它能够比较清楚地衡量模型在理解代码、定位问题、完成单次修改方面的能力,也确实推动了这一方向的快速进展。
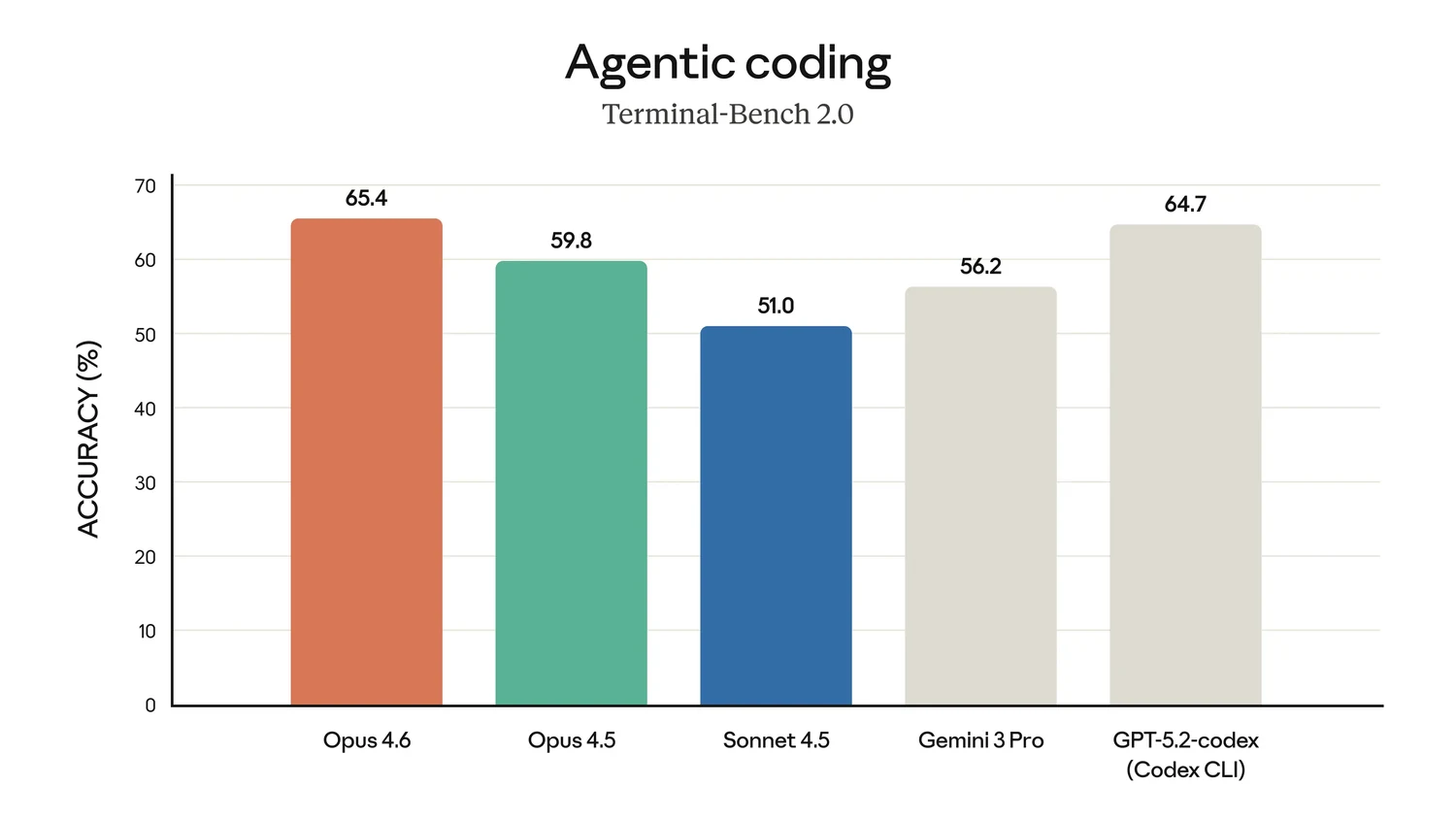
但它有一个非常明显的局限:它主要测的是这一次改得对不对,而不是这次改动会不会把后面的演化路径带偏。
这就像考试只看一道题是否答对,却不看你解题时埋下了多少后续隐患。你可以用非常脆弱、耦合很高、可扩展性很差的方式把当前测试跑通;在静态 benchmark 里,这样的答案和一个真正可维护、后续容易演进的实现,常常拿到的是同样的分数。
于是,很多模型之间的能力差距,会在这种评测方式下被显著压缩。
一个模型可能更擅长“短时间内拼出一个能过当前测试的 patch”;另一个模型则更擅长“做出对后续演化更友好的实现”。如果 benchmark 只看当前这一轮,那么后者的优势其实很难充分显现。但在真实工程中,后者的价值恰恰可能是决定性的。
二、真实软件工程考的不是“改对一次”,而是“能不能一路不把系统带崩”
SWE-CI 的关键贡献在于,它把评测对象从一次性 patching,改成了持续代码演化中的维护能力。
论文的核心观点非常直接:代码的可维护性,不可能只通过一次修改来判断;它只能在后续持续的演化中显现出来。
这也是为什么 Fig 1 会是整篇论文最重要的一张图。它对比了两种评测范式:
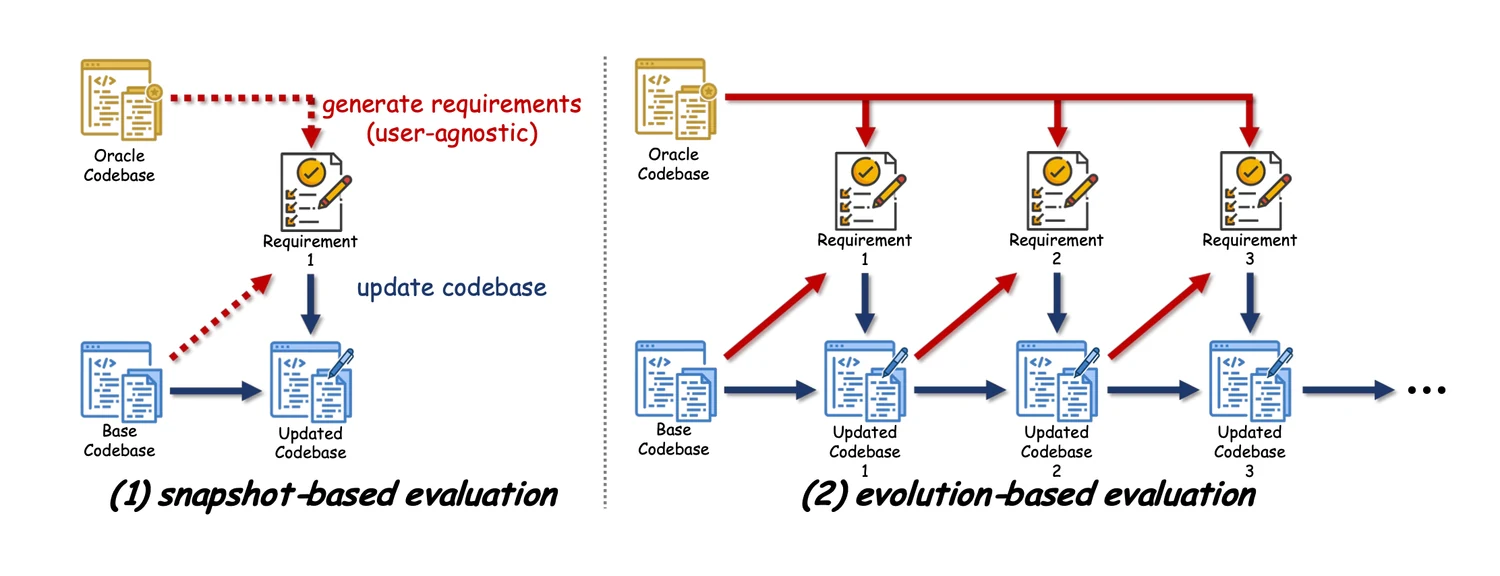
- 左边是传统的 snapshot-based evaluation:一次 requirement,对应一次 update
- 右边是 evolution-based evaluation:每一轮 requirement 都会根据当前代码状态和目标代码之间的差距重新生成,代码库在多轮迭代中持续演化
这背后的含义非常深。
在真实开发里,前一轮代码并不会在任务结束后被“重置”。你今天做的抽象、接口设计、模块切分、局部权宜之计,都会进入下一轮,继续影响后面的开发成本、改动难度与回归风险。
也就是说,真正重要的问题从来不是:“这个模型这一次能不能改对?”而是:“这个模型连续做很多轮相关修改之后,代码库会变得更容易维护,还是越来越难以收拾?”
一旦把问题换成后者,模型之间的差距就不再是几个百分点那么简单了。
因为在这种持续性任务里,错误不是一次性的,它会累积;回归也不是局部的,它会传染;设计决策不是中性的,它会不断放大后续开发的摩擦成本。
所以很多时候,所谓的“只差 5% 到 10%”,在真实工程里并不对应“只差一点点”,而可能对应着完全不同的工作体验:
- 一个模型能持续把系统往正确方向推
- 另一个模型虽然偶尔也能完成任务,但会不断引入回归、制造技术债、破坏演化路径
这就是为什么用户在真实使用中,会觉得某些 SOTA 模型与次一级模型之间并不是“略好”,而是“断层”。
三、这正是为什么 Claude Opus 4.6 的真实价值,往往比榜单分差看起来更大
如果把这个视角代入当前最强的编程模型,一个非常自然的观察就是:Claude Opus 4.6 之所以在真实软件工程中的体感优势经常远大于榜单上的分差,并不奇怪。
原因并不神秘。不是因为用户“主观滤镜”更强,也不是因为榜单完全无效,而是因为很多传统 benchmark 在结构上更容易测出“单轮任务的平均正确率”,却不容易充分测出以下这些在真实工程中极其关键的能力:
- 多轮迭代中的稳定性
- 对回归的控制能力
- 设计决策对后续演化的友好程度
- 复杂上下文中的长期一致性
- 在持续维护中避免把系统逐步带偏的能力
而这些能力,往往恰恰是顶级模型和普通模型拉开真实差距的地方。
在单轮任务里,很多模型都能“像模像样地做出一个答案”;但在持续任务里,问题会迅速变成:
- 第二轮还能不能接住第一轮留下的结构?
- 第五轮之后会不会开始出现越来越多的兼容性问题?
- 第十轮之后,代码库是更清晰了,还是已经被补丁式修改搞得难以演化?
SWE-CI 之所以重要,就在于它试图把这些问题正式纳入评测。
从论文结果看,Claude-opus-4-6 不仅总体 EvoScore 领先,而且在 zero-regression rate 这项指标上表现尤其突出。论文将 zero-regression rate 定义为:在整个长期维护过程中,从未引入回归的样本比例。
这个指标很有现实意义,因为它测的不是“偶尔高光时刻有多亮眼”,而是“在持续维护中你到底靠不靠谱”。
论文中的结果非常值得注意:大多数模型在这项指标上都不高,而 Claude-opus-4-6 的表现明显更强。这意味着它的优势不只是“平均多做对几题”,而是更接近一种真实工程里更稀缺的能力:在持续演进中保持系统稳定、不轻易把已有正确性打坏。
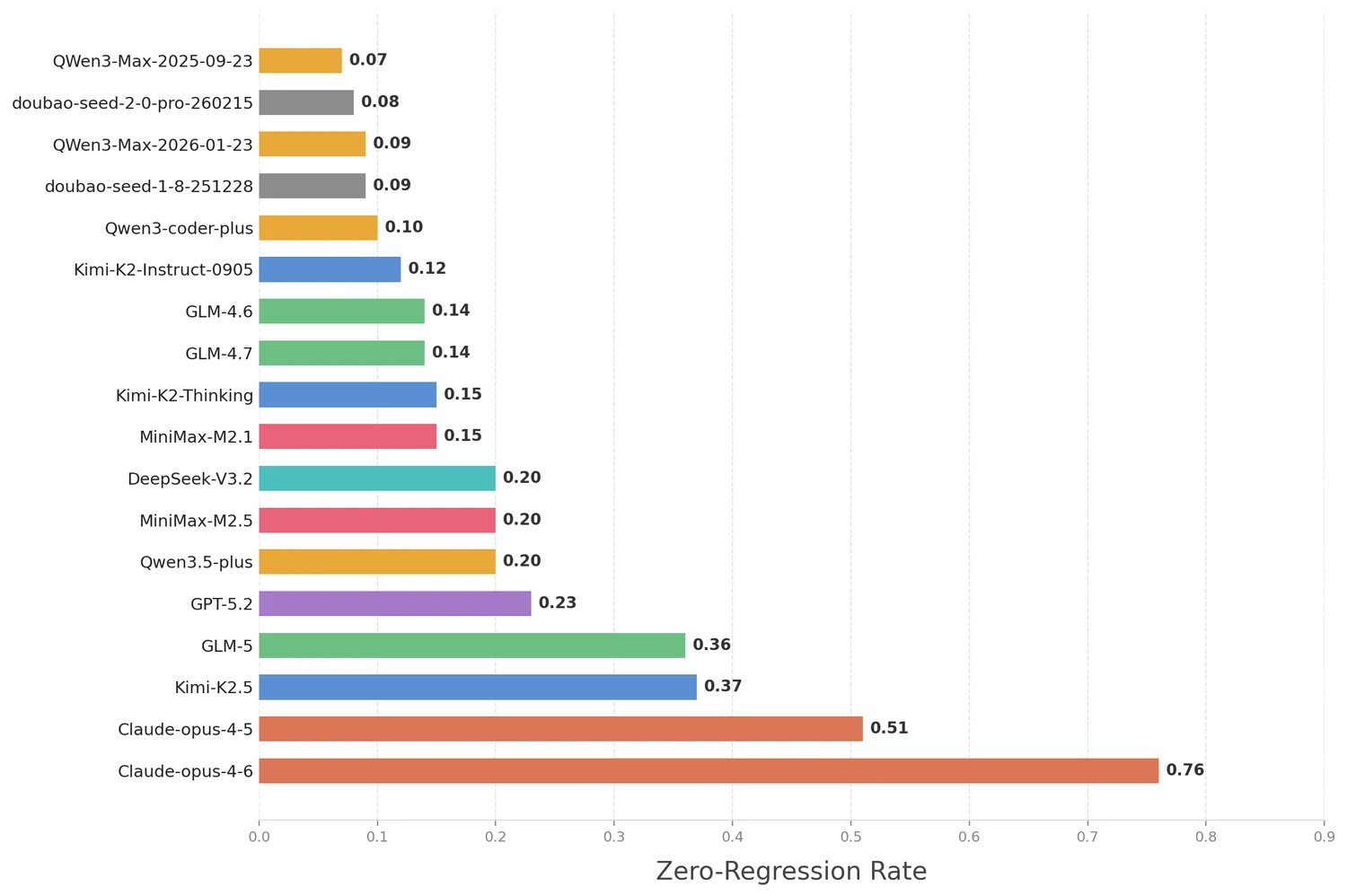
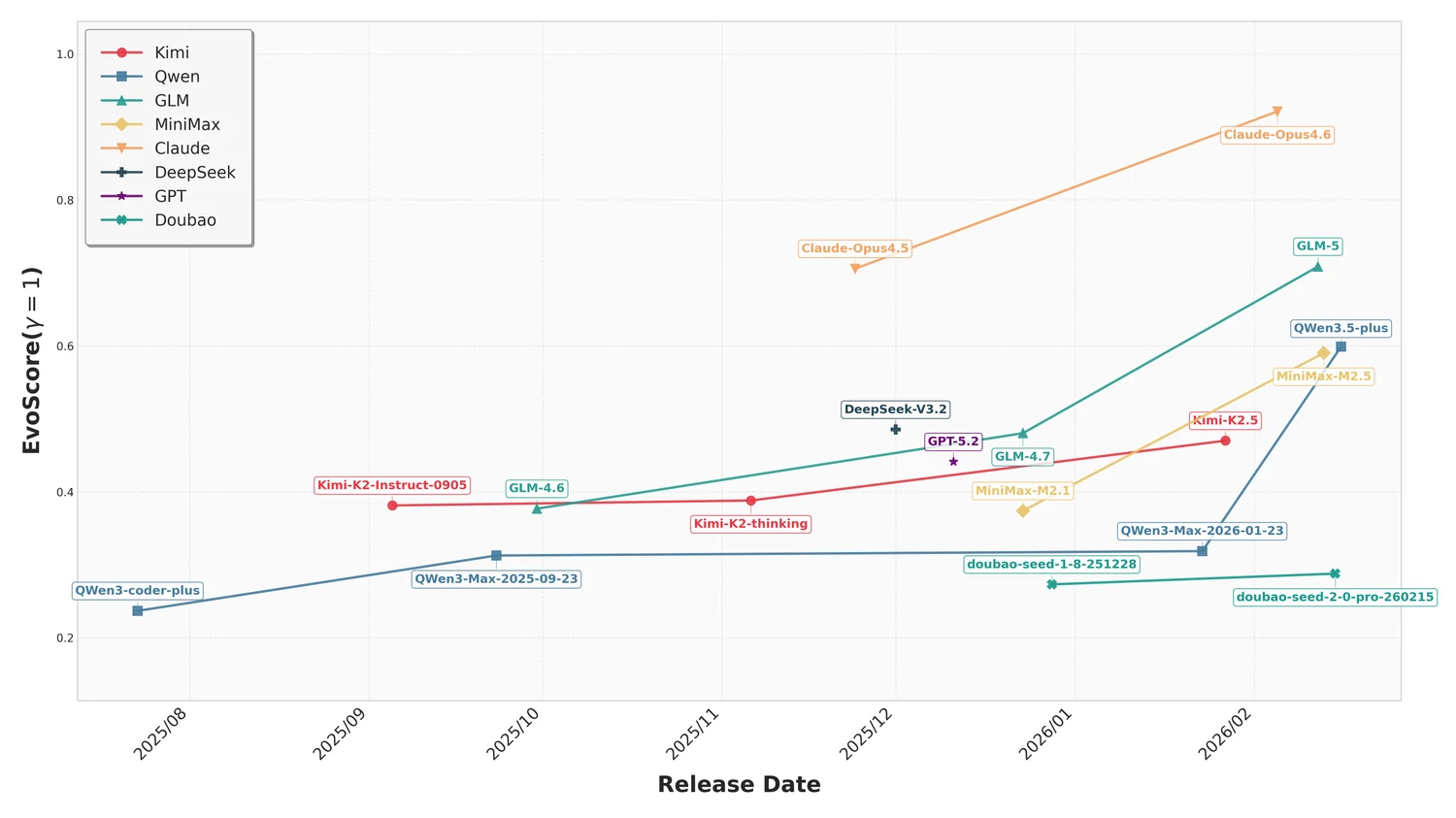
这类差异,一旦落到真实工作流里,就绝不会只是榜单上的几个点。因为在真实团队协作中,最昂贵的从来不是“这轮任务没做完”,而是:
- 做完了却留下隐患
- 表面完成了却破坏了已有逻辑
- 当前收益不大,但为后续维护埋下持续成本
- 任务越做越多,代码库越来越难接着演进
所以很多工程师最终形成的体感会是:第一名不是“更聪明一点”,而是“终于开始具备一定工程可用性”;后面的模型虽然也会写代码,但离真正可用还差着一道很深的鸿沟。
SWE-CI 把这种体感,首次比较系统地转化成了可讨论、可衡量的 benchmark 语言。
四、这篇论文解释了为什么“小任务评测很好看”,却依然解释不了大型工程里的真实体验
这也是 SWE-CI 的第二层价值。
它不仅解释了为什么 SOTA 模型的重要性会被低估,也解释了另一个行业里越来越普遍的困惑:为什么很多模型在小任务、小 demo、小评测集上看起来已经非常强了,但一旦放进真实大型工程,体验却和预期相差很远?
原因在于,二者面对的根本不是同一类问题。
很多小任务评测关注的是:
- 功能能否快速做出来
- 局部逻辑是否正确
- 一次性交付是否成功
而真实企业工程,尤其是大型 monorepo、长生命周期系统、多人协作环境,更关心的是:
- 这次改动是否与现有架构一致
- 会不会破坏其他模块的隐含约束
- 接口是否为未来演进留下空间
- 有没有引入后续难以清理的技术债
- 在多轮迭代之后,系统整体是在变好还是在劣化
前一种任务更像是“把东西做出来”;后一种任务更像是“把系统长期维护下去”。
这两种能力当然有关联,但并不等价。一个模型可以非常擅长 vibe coding,几分钟内搭出一个令人惊艳的 demo;但这并不意味着它也能胜任大型工程里的长期架构演进与维护工作。
尤其在企业内部的复杂代码库里,真正困难的地方,往往根本不是“写出一个功能”,而是:
- 在历史包袱之上继续演进
- 在复杂依赖关系里避免局部最优
- 在多人协作环境里维持抽象一致性
- 在不断新增需求时保持代码库不劣化
从这个角度看,SWE-CI 其实在提醒整个行业:我们不能把模型在小任务上的亮眼表现,直接外推出它在大型真实工程中的长期维护能力。
如果评测对象只是一系列足够简单、足够局部、足够短链路的问题,那么模型之间的差距确实可能显得没有那么大。但一旦任务变成持续演化过程,原本被隐藏的能力差距就会迅速显现。
五、SWE-CI 的方法贡献,在于它试图用“未来演化表现”去反推当前设计质量
从研究设计上看,SWE-CI 最有意思的地方,是它没有直接声称自己“完整衡量了 maintainability”,而是选择了一个相对克制、也更可操作的路径:用未来修改过程中的功能正确性轨迹,来近似衡量当前实现的可维护性。
论文里有两个关键指标。
第一个是 Normalized Change。它用来描述当前代码相对于 base 的净改进或净退化,统一衡量“做对了多少”和“搞坏了多少”。
第二个是 EvoScore。它对多轮 Normalized Change 做加权汇总,而且通常会给后期轮次更高权重。其背后的理论假设是:如果一份代码真的更可维护,那么它在未来连续修改中应该能保持更稳定、更可持续的收益;反之,如果它只是靠局部取巧换来短期收益,后续迭代中往往会出现回归、失稳、甚至整体性能下滑。
![]()
这其实是一个很聪明的思路。因为 maintainability 本身是一个高度抽象、难以直接观测的概念,而 SWE-CI 试图绕开“直接定义好代码长什么样”的困难,转而去观察:一份代码在未来持续改动时,到底会不会越来越难改、越来越容易出错、越来越难保持正确性。
这当然不是 maintainability 的全部,但它抓住了其中一个非常关键、而且与工程现实高度相关的维度。
六、数据集与评测协议为什么值得重视
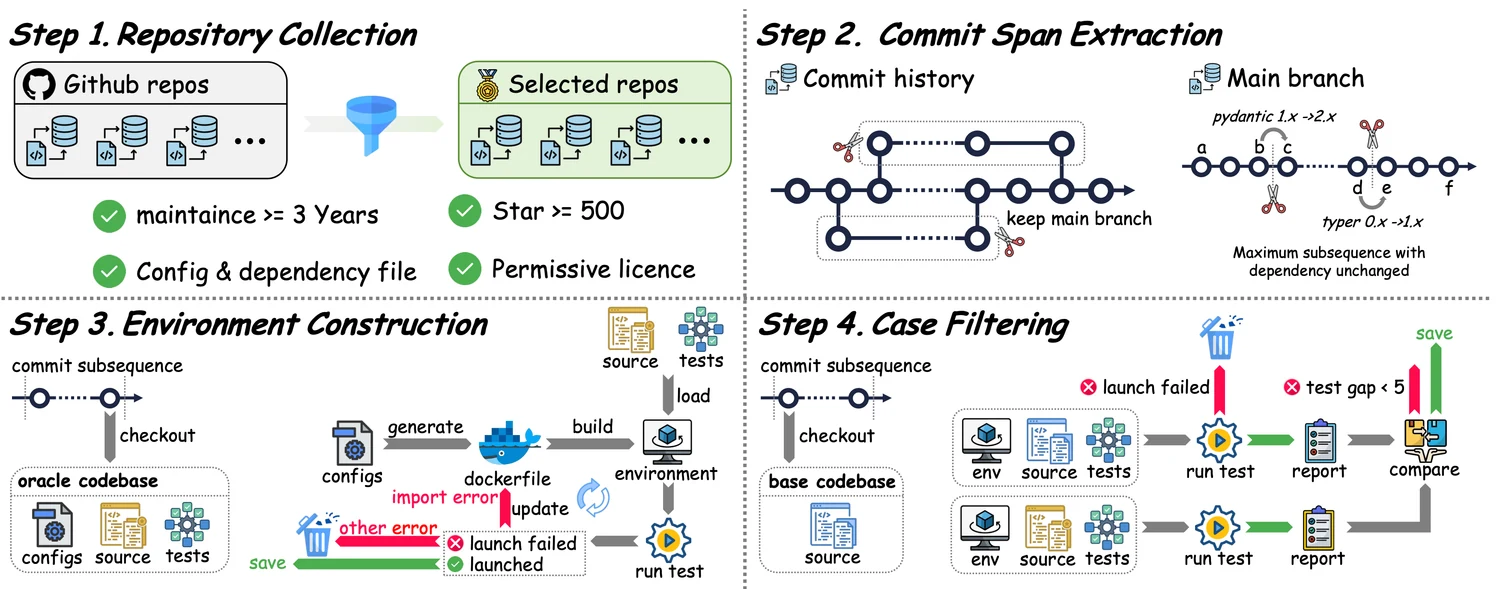
SWE-CI 并不是随手从几个知名仓库里抽几个任务来评估,而是试图系统性构造一个更接近真实 CI 与长期演化场景的数据集。
论文最终构建出 100 个样本,来自 68 个不同仓库,平均跨度 233 天、跨越 71 个连续 commits,并要求 base 到 oracle 之间存在足够显著的代码变化。
Fig 2 展示了数据构建流程:从 GitHub 上筛选 Python 仓库,过滤长期维护、测试基础、许可证与配置条件,再抽取依赖保持稳定但代码持续演化的 commit span,构建环境并运行测试,最后经过多轮质量过滤,得到可复现任务。
而 Fig 3 给出了它的 dual-agent evaluation protocol:
- Architect 根据当前代码与目标代码之间的测试差距,归纳 requirement
- Programmer 再根据 requirement 做计划与实现
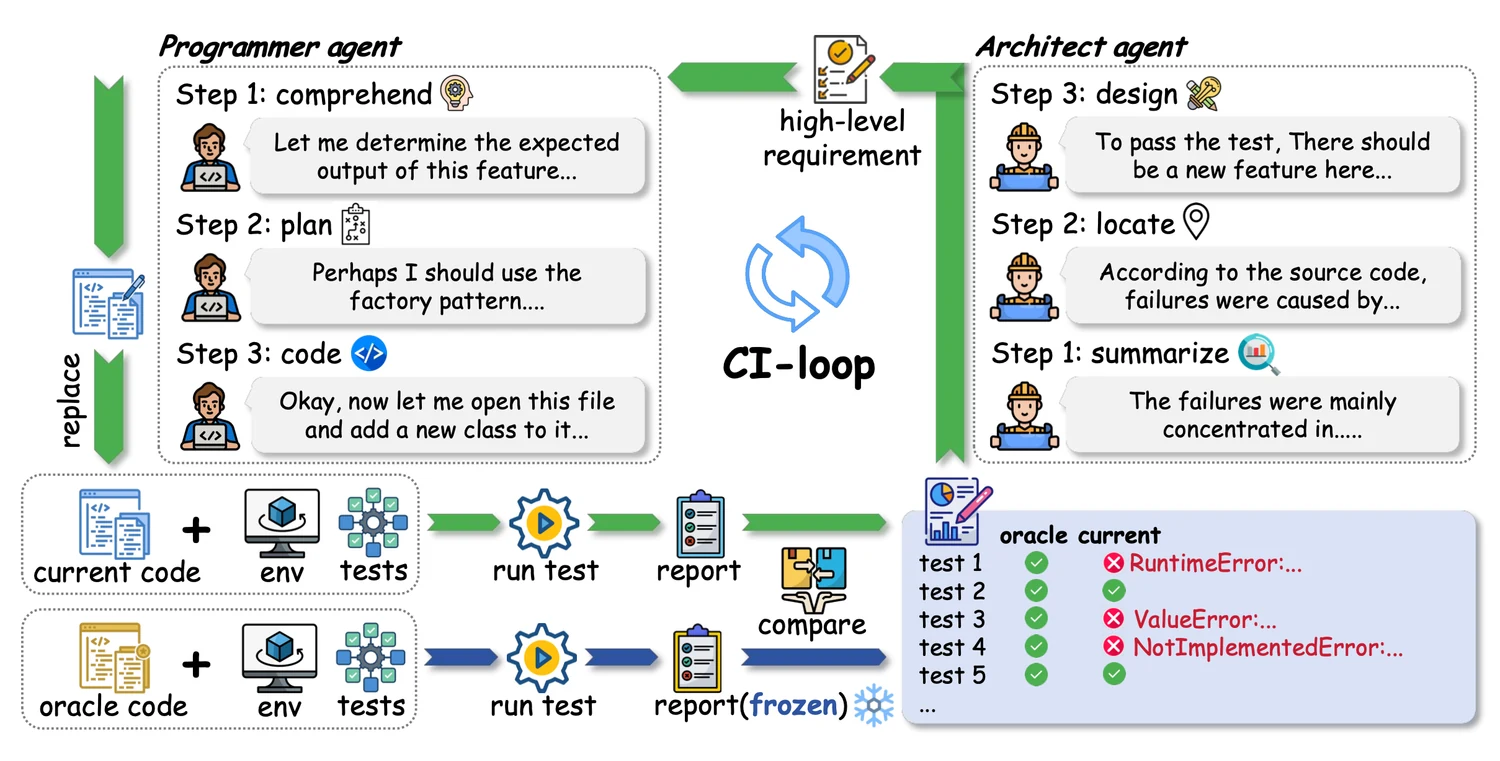
这个协议的意义不只是“多智能体更炫”,而是更贴近真实软件工程中“需求抽象 → 编码实现”的工作链条。它测的不再只是 patching,而是更接近“理解演化目标、生成需求、完成维护实现”的综合能力。
七、不过,SWE-CI 也不是“已经解决了长期维护评测”的终点
如果要更严谨地看,这篇论文并不是在宣称“自己已经完整评估了软件可维护性”。
它更准确的贡献应该表述为:它把长期代码演化中的功能正确性与回归控制,作为 maintainability 的一个可操作代理指标,系统地纳入了 benchmark。
这意味着它仍然有边界。
例如,它不一定充分覆盖:
- 架构优雅性
- 命名与可读性
- 文档质量
- 团队协作可理解性
- 长期模块边界设计的审美与合理性
这些维度同样重要,只是更难以大规模自动评测。
但即便如此,SWE-CI 依然是一个非常重要的推进。因为在它之前,行业里大量讨论“代码能力”的 benchmark,更多仍停留在“能不能一次做对”这个层面;而 SWE-CI 至少把问题往前推进了一步:能不能持续做对,能不能越做越稳,而不是越做越乱。
八、真正值得重视的结论,不只是“第一名很强”,而是“整个行业离真实工程还很远”
如果只从营销角度看,这篇论文很容易被解读成一句话:Claude Opus 4.6 很强,而且比后面模型强很多。
这当然是论文传达出的一个现实结论,而且从真实体验角度看,这个结论很有解释力。
但如果只停在这里,就会低估这篇论文更重要的另一层含义:即便是当前最强的模型,距离大型真实工程里的长期维护能力,依然还有明显差距。
这也是为什么很多工程团队的实际体验会是:
- 在小任务上,模型已经相当惊艳
- 在 demo 场景里,模型常常给人“几乎能替代部分开发工作”的错觉
- 但一旦进入复杂工程、长期演进、多人协作、高一致性要求的环境,模型的可靠性和可维护性问题就会迅速暴露出来
换句话说,SWE-CI 一方面告诉我们:不要用“只差几分”去低估 SOTA 模型的真实价值。
另一方面也提醒我们:不要因为模型在小任务上表现亮眼,就误以为它已经真正具备了大型工程中的持续维护能力。
这两点其实同样重要。
前者解释了为什么第一名往往比数字看起来更值钱;后者解释了为什么即便是第一名,也还远远不能让人对真实软件工程掉以轻心。
结语:SWE-CI 让我们终于开始认真讨论“代码能不能活下去”
如果要用一句话概括 SWE-CI 的意义,我会说:它的价值不只是提出了一个新的榜单,而是把“代码能不能长期活下去”这个真正属于软件工程核心的问题,正式带进了大模型评测。
这也正是为什么它对今天的编程模型讨论特别重要。
它帮助我们理解:
- 为什么
Claude Opus 4.6这样的 SOTA 模型,在真实工程中的优势常常远大于榜单上那几个百分点 - 为什么小任务、小评测集里的漂亮成绩,不能简单外推到大型真实工程
- 为什么“会写代码”离“会维护代码库”之间,仍然隔着一道巨大的鸿沟
在这个意义上,SWE-CI 并不只是给出了一个新的评价方式。它更像是重新校准了我们看待编程模型能力的尺度:真正决定模型工程价值的,未必是它能不能漂亮地完成某一次修改,而是它能不能在持续迭代中,不断把系统往更健康的方向推进。
而从这个标准看,SOTA 模型的重要性会被放大,当前模型能力的边界也会同时暴露出来。
这或许正是这篇论文最值得认真读的地方。