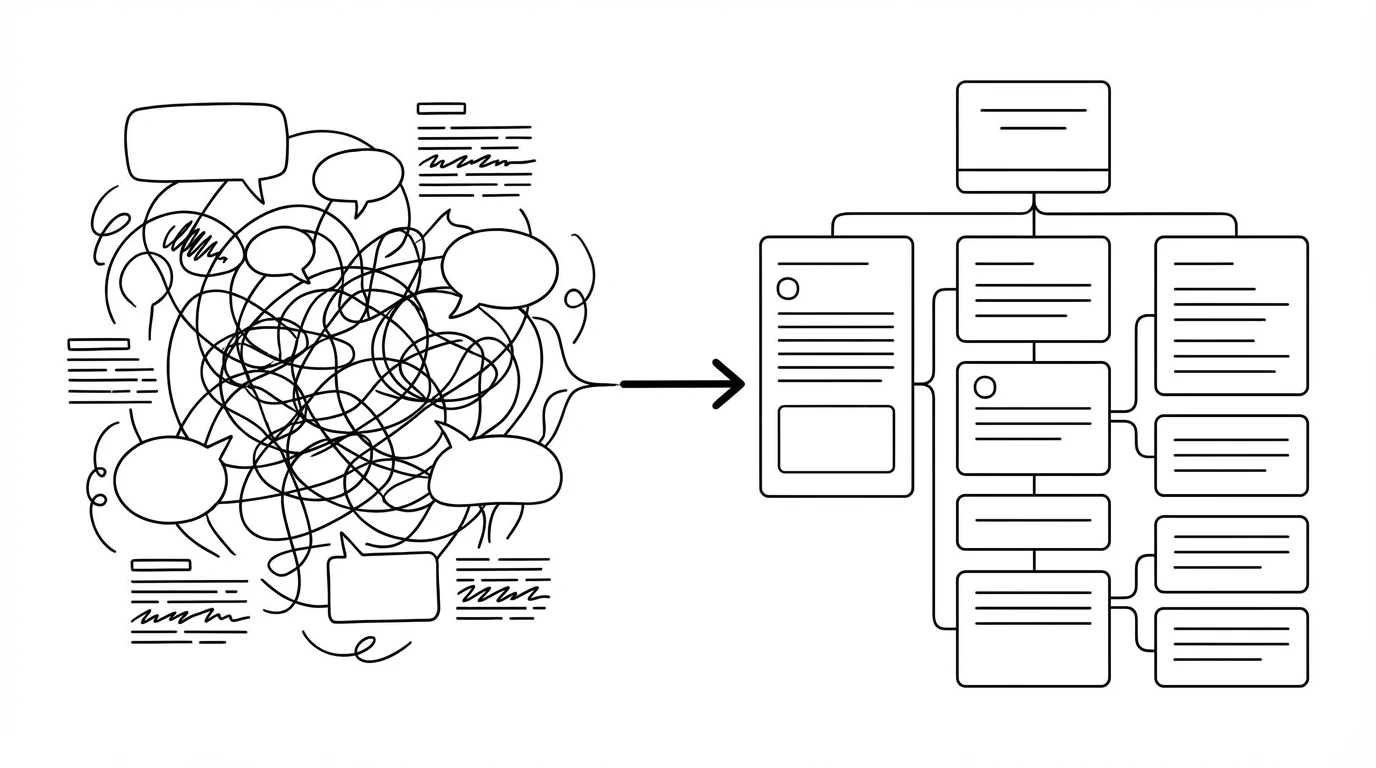
别再只打字编程了,语音才是 AI 时代的输入方式
什么是 Voice Coding
这段时间我越来越常用语音跟 🦞OpenClaw 或 Coding Agent 沟通。甚至很多时候会刻意少打字,多说话。
以前我常常会卡在“怎么把 prompt 写清楚”——我明明脑子里已经有完整的上下文,已经想清楚了背景、风险、约束:为什么要这么改、哪些东西不能动、风险点在哪里……
但一旦开始打字,这些信息会被我自己压缩成几句话。写出来的内容越短,AI 越容易漏掉关键前提。
然后就会出现那种很常见的情况:AI 给的方案看起来很合理,但跟我实际的约束不对齐;我得不断补充前提、纠偏、重来;最后“省下来的打字”,变成了“多出来的返工”
后来我发现问题不在 AI,也不在我“不会写 prompt”,而是输入带宽太低:打字天然会让你惜字如金(打错字了也会下意识去删除更正,打断注意力)而语音更容易把脑子里的隐含信息完整倒出来。对 Coding Agent 来说,这些隐含信息,往往比你写得多不多、有没有错别字更重要。
🧙
我现在的做法是:
- 用语音把任务讲清楚(背景、目标、约束、验收、边界情况)
- 让 Coding Agent 先出计划,再按计划施工,过程中继续用语音补充细节或纠偏 关键点不在“语音转文字”,而在于:你更愿意把隐含信息说出来。打字更像在“写需求文档”(你会下意识删掉很多背景),语音更像在“跟同事结对/做设计评审”(你会自然把关键约束补齐)

语音能给出更多“有效信息量”(不是更长,是更完整)
AI 跑偏很多时候不是能力问题,是信息差问题。
打字时我经常会省略掉这些内容:
- “这个模块历史包袱很重,别大改,先做最小改动”
- “这个接口外部在用,不能破坏兼容性”
- “先别追求优雅,先跑通并补测试”
- “这个东西线上出过事故,风险点在这里”
这些其实才是“让 AI 做对事”的关键条件。语音输入时,我反而更容易顺嘴把这些都讲出来。这些不是“额外的碎碎念”。对 Agent 来说,它们决定了解题方向。
语音更贴近思考速度,表达更连续
另一个很现实的点:思考速度比手打快。
打字会把注意力拉到措辞和排版上,让我频繁进入“编辑模式”:删字、改句、纠结措辞;语音则更像把思路直接倾倒出来,把脑子里的内容直接说出来。它不一定更正式,但往往更接近完整版本。
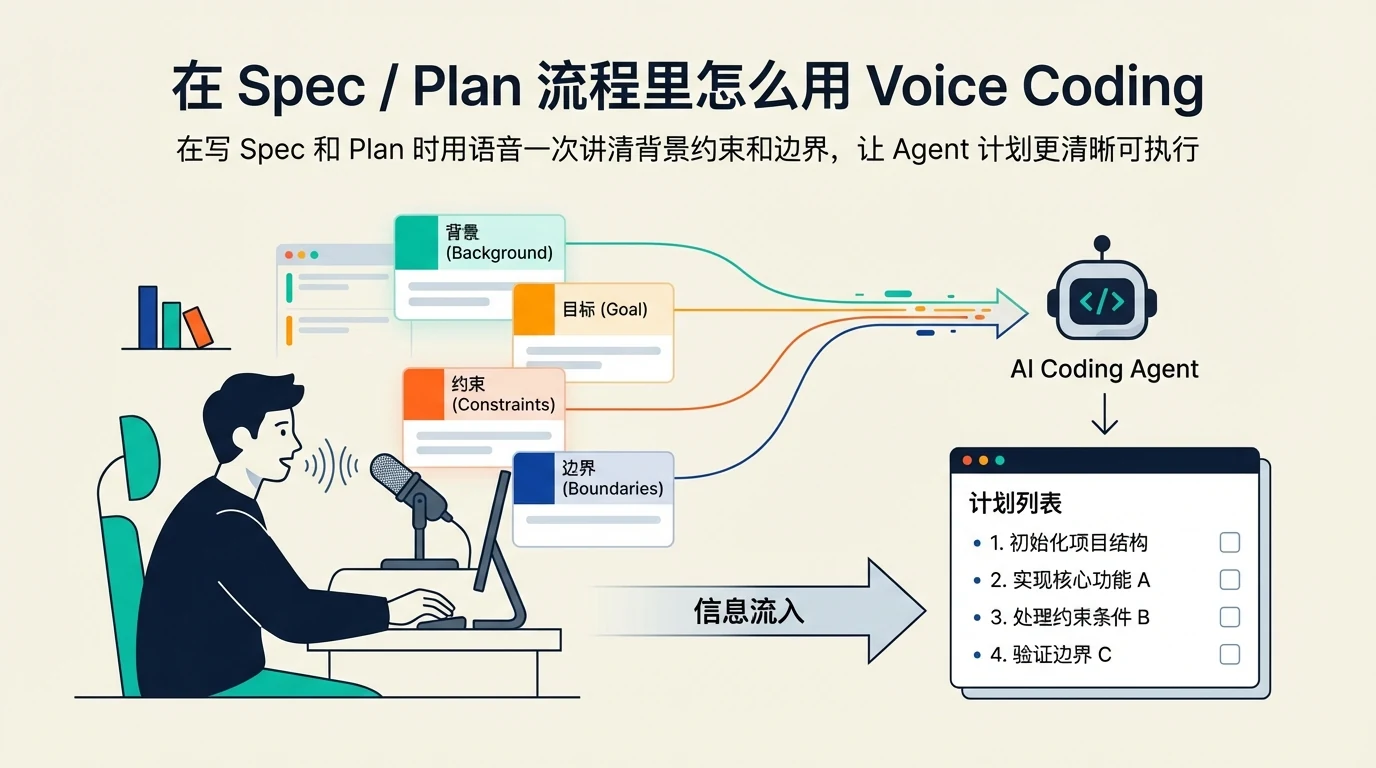
我在 Coding 的过程中通常会先做计划。
如果你走过 Spec Coding 的流程,就会很熟悉:先把需求拆解成一系列可落地的子需求点;然后针对每一个子需求点,分别做 Plan / Spec。
而 Voice Coding 在这里最有价值的地方,是:你可以像跟新同事交接一样,一股脑把信息都讲出来。你越愿意讲清楚,Agent 产出的 Plan 就越清晰、越像一个靠谱的工程计划。
我一般会覆盖这些信息(不要求一次说得很漂亮,先把关键信息讲到位):
- 背景与目标:为什么要做、要做到什么程度
- 约束与验收:哪些不能动、哪些必须兼容、怎么验证算完成
- 边界与隐含信息:错误路径、空值、极端输入、已知历史坑
- 架构与技能:希望沿用的设计方式、模块边界、涉及技术点
- 可参考代码:仓库里类似实现的位置,或者你希望它对齐的写法
你也可以直接把参考路径念出来,比如“目录在…/…,类似实现是…/…”。这类信息对 Plan 的质量影响很大。
这其实非常像跟刚入职的同事交接或者给实习生分配任务,当面做一次 One-on-One 把需求讲透:先把信息喂饱,Agent 产出的 Plan / Spec 才容易一次对齐。
软件怎么选:从“纯转写”到“意图理解” 差别非常大
语音识别软件这块我试用过不少。
识别准确率本身,各家差距没那么大。真正影响体验的,是后处理:它到底能不能把口语变成一段适合交给 Agent 执行的输入。
微信输入法 / 豆包输入法:能用,但属于“上一代转写”
微信输入法最近的新版本(内测)已经支持 FN 键语音输入。(微信 Mac 客户端也自带了一样的语音输入功能)从“可用性”来说它没问题——你说话,它出字,足够快。
豆包输入法 Mac 版目前在内部测试中(最新版本还是 25 年 11 月的),语音输入体验主观上感觉不如 iOS 版。
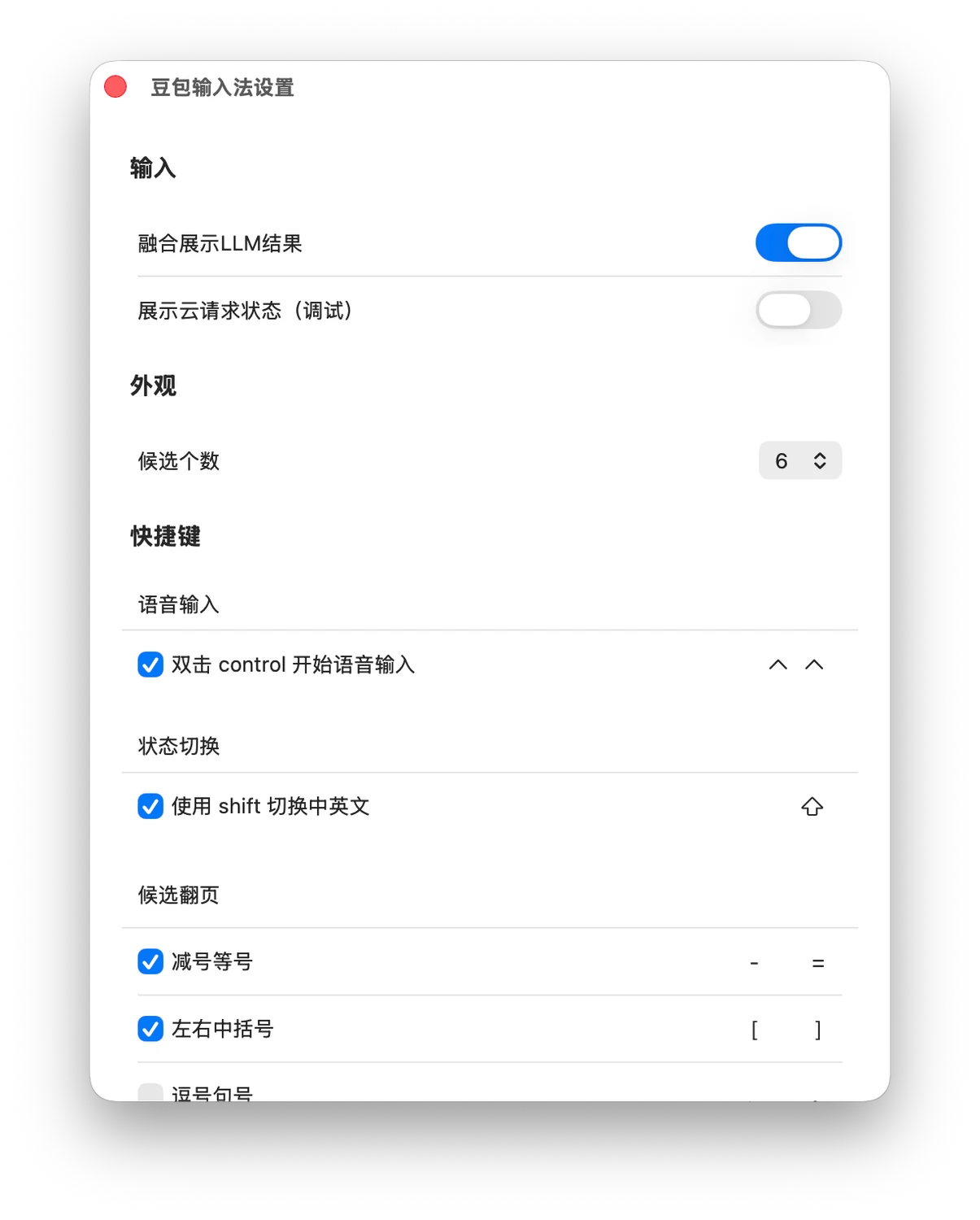
这类工具的特点是:你说什么,它就写什么。语气词、停顿、反复修正都会保留。
聊天场景这反而是优点,文本看起来更像真实口语。
但在 Coding 场景下就不太理想。即便大模型足够聪明,面对一堆口水话也能大概理解意图,但这种纯转写仍然会带来两个典型问题:
- 信息干扰
比如你先说了方案 A,讲到一半意识到不对,立刻改口说应该用方案 B。
在纯转写里,A 的错误信息已经进来了;你再讲 B,等于把“正确 + 错误”一起喂给 Agent。它当然可能判断出 B 更合理,但也更可能在某些细节上被 A 干扰。
- 注意力机制陷阱(越强调不要什么,越容易被误导)
有个经典的心理学测试:“别去想那只粉色大象”,当你告诉自己“不要想起”什么的时候,你已经开始想了。
大模型的注意力机制在某些场景下也会类似:你越反复强调“不要 A”,A 这个 token/概念反而更容易被模型关注到,最终在生成时以某种形式“冒出来”。
所以在我自己的使用习惯里:配合 Coding Agent 做严肃的 Plan / 实现时,我不会使用微信/豆包输入法这种纯转写链路。不是说不能用——而是它更适合聊天、临时记两句;对 Coding 来说它的噪声和干扰成本偏高。
Typeless:开箱即用,而且是真的“会整理”
接下来我最推荐的是 Typeless。
省心是一方面,更关键的是输出质量稳定。它的内置润色 Prompt 明显是精心打磨过的:同一段口述在不同语境下,输出都比较符合预期。
🕹️
全文介绍的唯一一个付费软件,每月 12 美元(前 30 天免费试用) https://www.typeless.com/
😘 使用邀请码注册,双方均可获得 5 美元代金券:https://www.typeless.com/refer?code=FC1M32V
我最常遇到的两个场景:
- 想口语化表达时,它不会突然变得过度严谨、过度结构化
- 想写得正式一些(例如喂给 Coding Agent 出 Plan / 改代码)时,它又能把表达收得更专业

- 开箱即用
Typeless 几乎没有什么需要你设置的地方。打开就能用。
对我来说这点非常重要:Coding 最怕“工具链摩擦”。你如果每次用之前都要调参数、选模型、想格式,最后一定会变成偶尔用一下。
- 智能化理解(能把你自己口述时的纠错吸收掉)
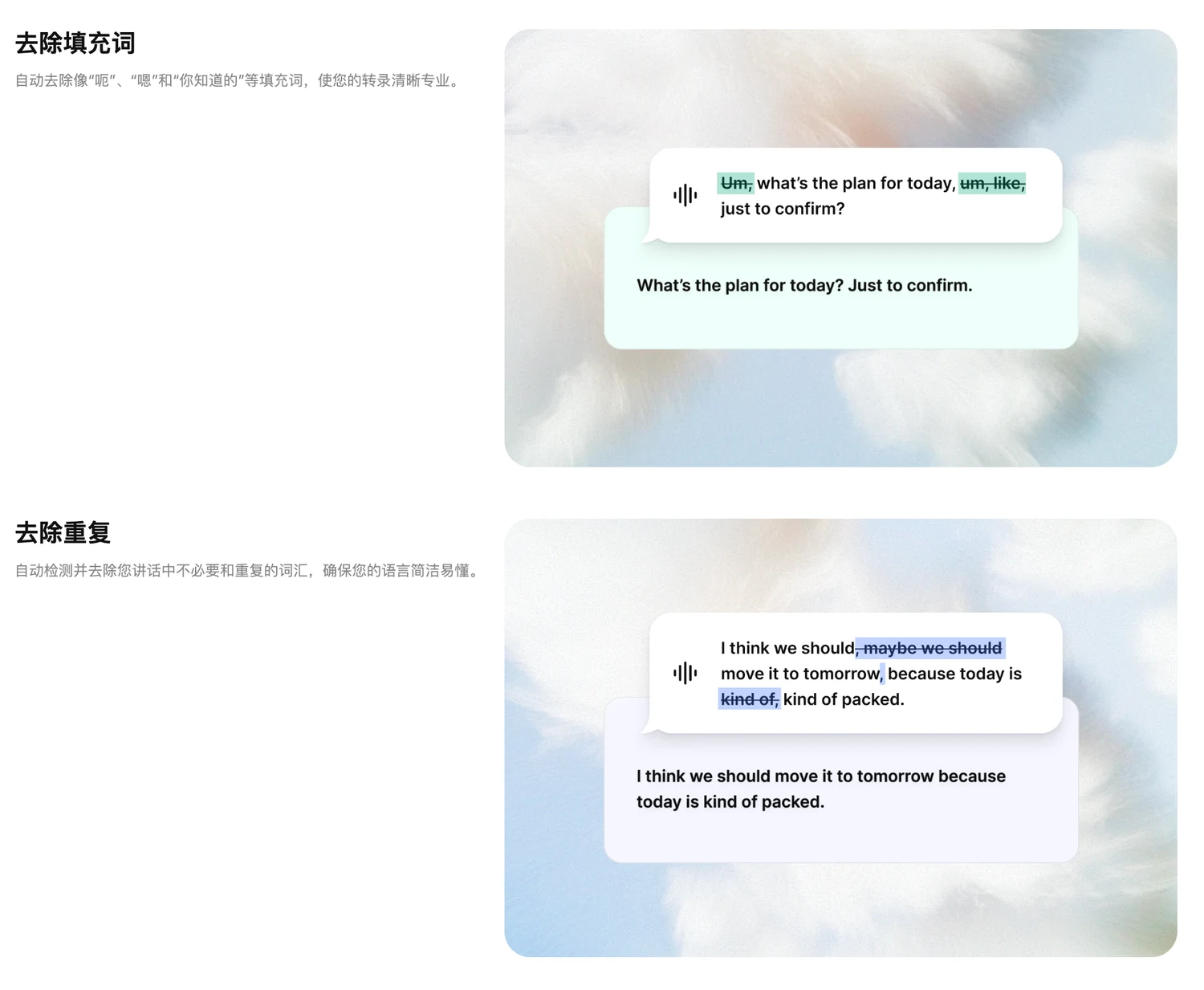
它最厉害的地方在于:不是把你说的话逐字记录下来,而是会用大模型去理解你的意图。
比如你在口述时:
- 先说了第一点、第二点、第三点
- 讲着讲着突然意识到第二点说错了
- 于是补一句:“第二点我刚才说错了,应该是……(纠正版本)”
Typeless 最终给你的文本,往往已经把错误的部分订正掉了,输出结果更像“你真正想表达的那版”。
- 恰到好处的润色
它的排版、断句、段落化做得很刚好:更有条理,但又不会像“AI 写作”那样刻意。没有被传染经典的 GPT 5.2 味道


你把它的输出丢给 Coding Agent,体感上会更稳、更像一段可以直接执行的任务说明。
- 持续学习能力
随着你使用时间增加,它会越来越理解你。
比如可能因为口音问题,它会把 “Claude /klɔːd/ Code” 识别成 “Cloud /klaʊd/ Code” 。这时你可以选中那段词,再按下 Fn + Space 快捷键说这样一句话:
我这里说的 Claude Code 是指 Anthropic 的那个 Coding Agent ,不是云朵那个 Cloud。
它改对之后,后面在类似语境里就更容易自动纠正。

其他免费的语音输入法
另外一类比较火的,是 闪电说 / AutoGLM 智谱输入法 / LazyTyper 等可配置程度较高的免费输入法。
智谱输入法
智谱输入法的优点是开箱即用:它内置了自家的语音模型服务,免费使用,同时也能配置润色 Prompt。
https://autoglm.zhipuai.cn/autotyper/
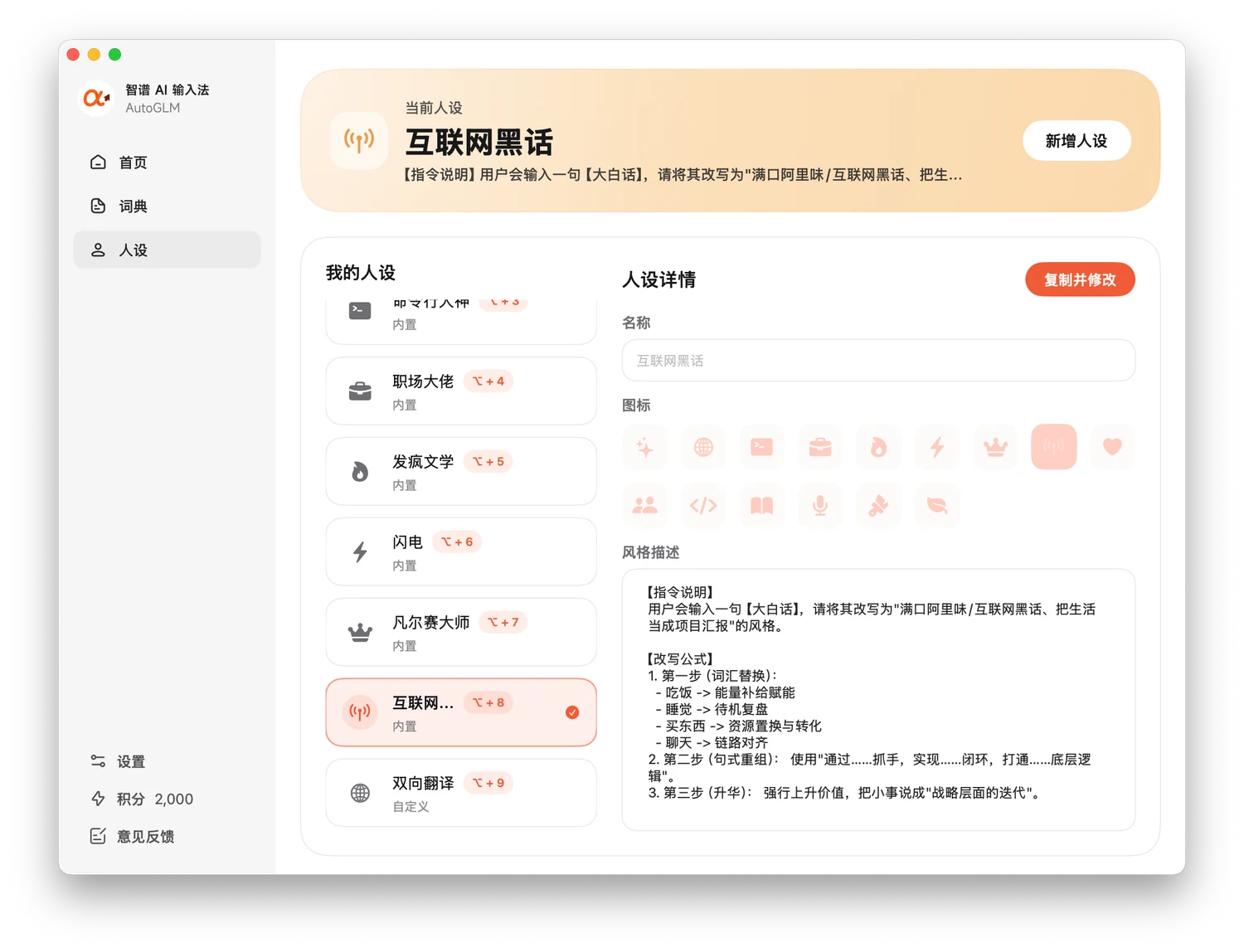
限制也很明确:模型只能用它内置的(免费,但你不能换成别的)。
闪电说
闪电说的可自定义空间更大。语音识别服务可以用豆包语音大模型或其他在线语音服务(需要你自己申请 API Key),也可以使用本地离线模型。
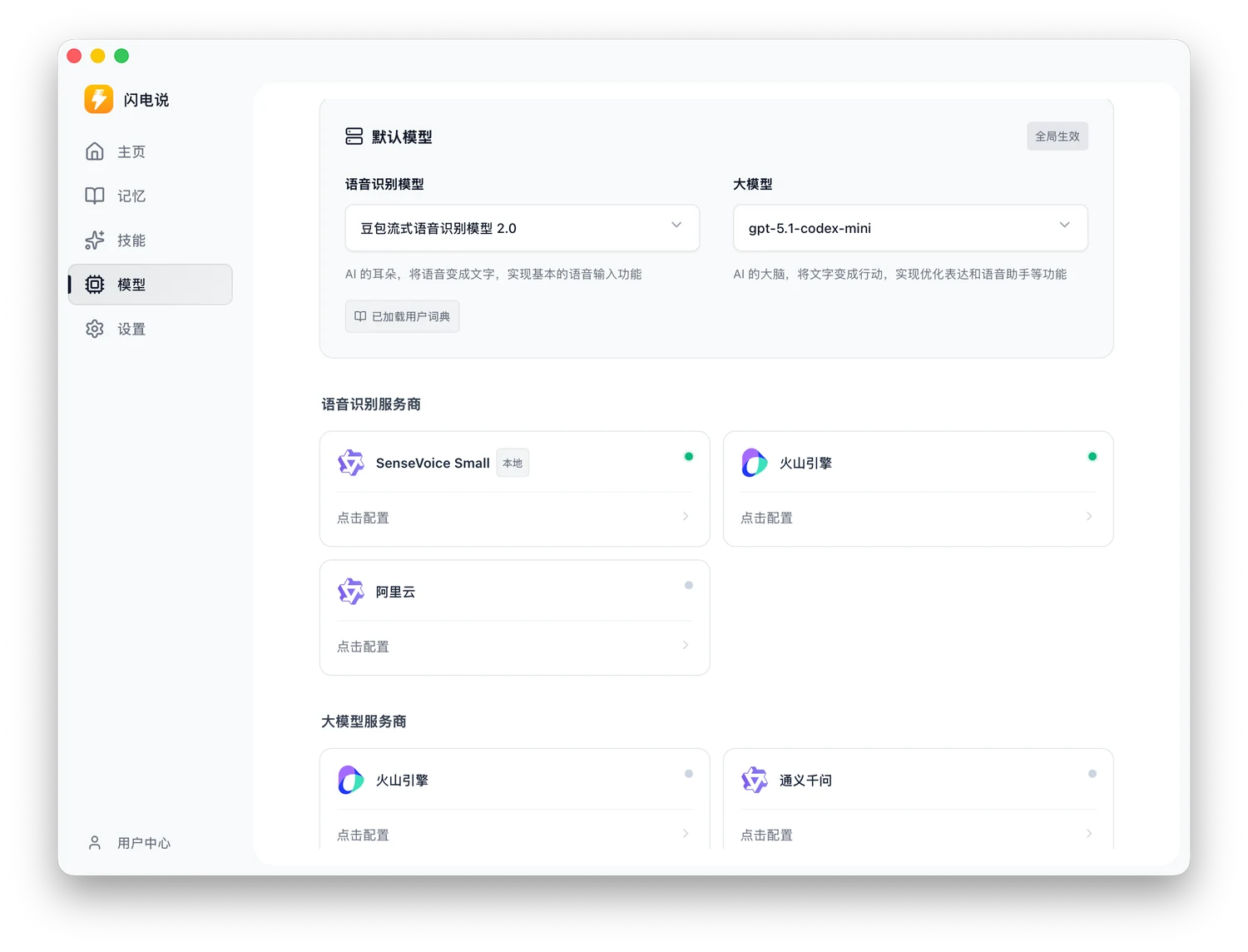
同时,润色后处理服务也可以自己选择 LLM 提供商,自己提供 API Key
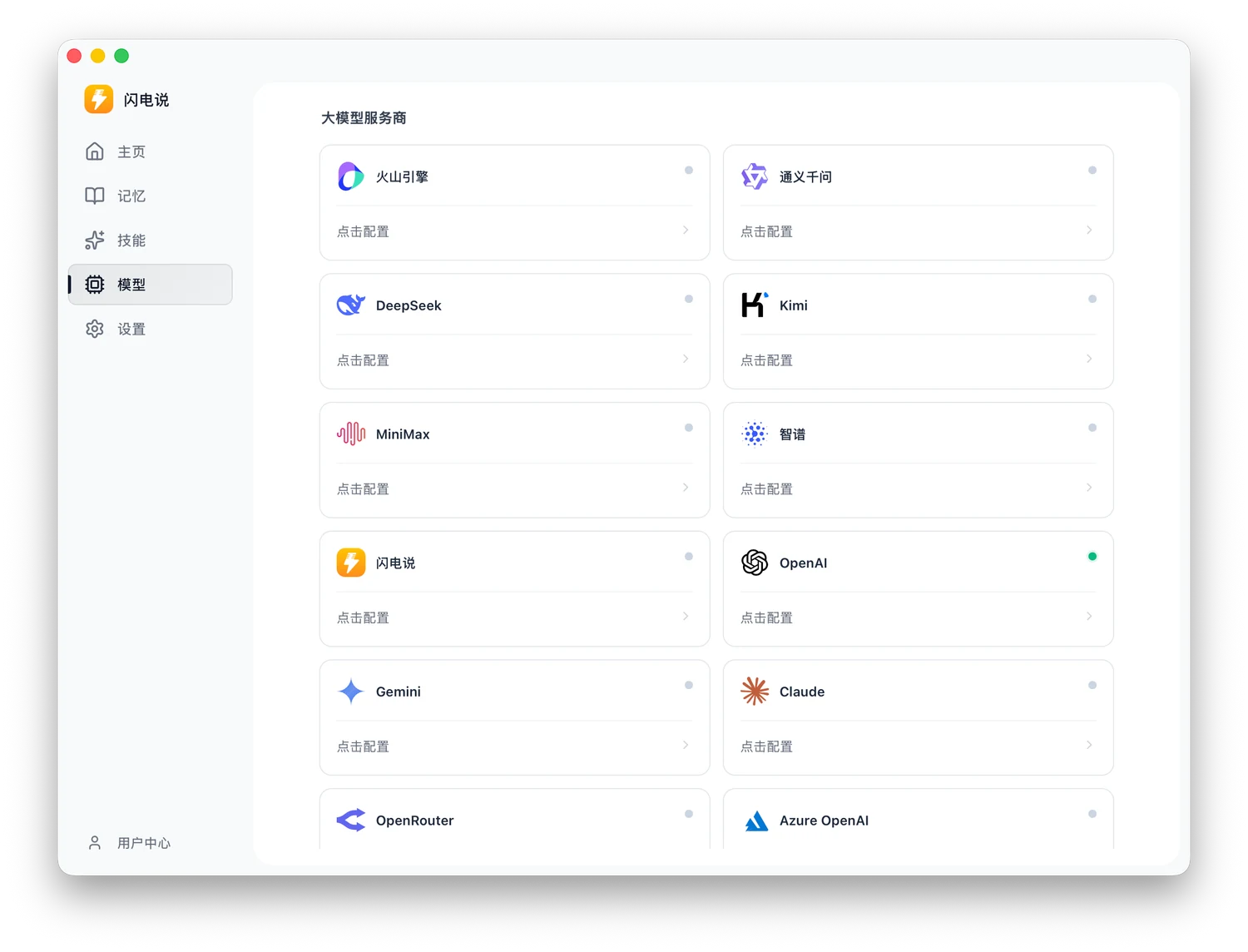
润色自定义方面可以无脑简单勾选上“自动结构化”、“口语过滤”,也就是 App 内置的润色 Prompt,你也可以完全自定义你自己的后处理润色提示词。
LazyTyper
也是类似闪电说的路线,但更框架化。它可以分别接入语音识别模型和后处理大模型。
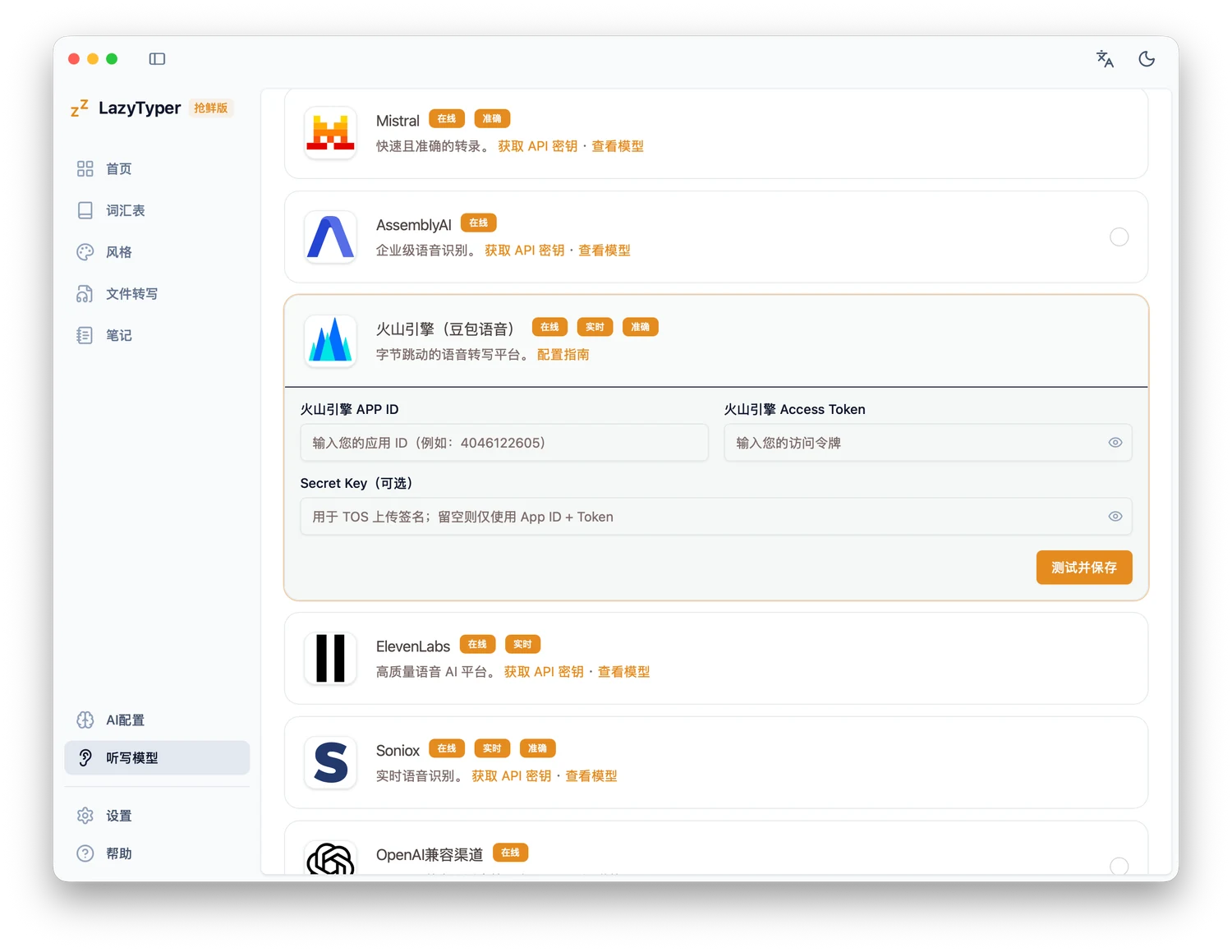
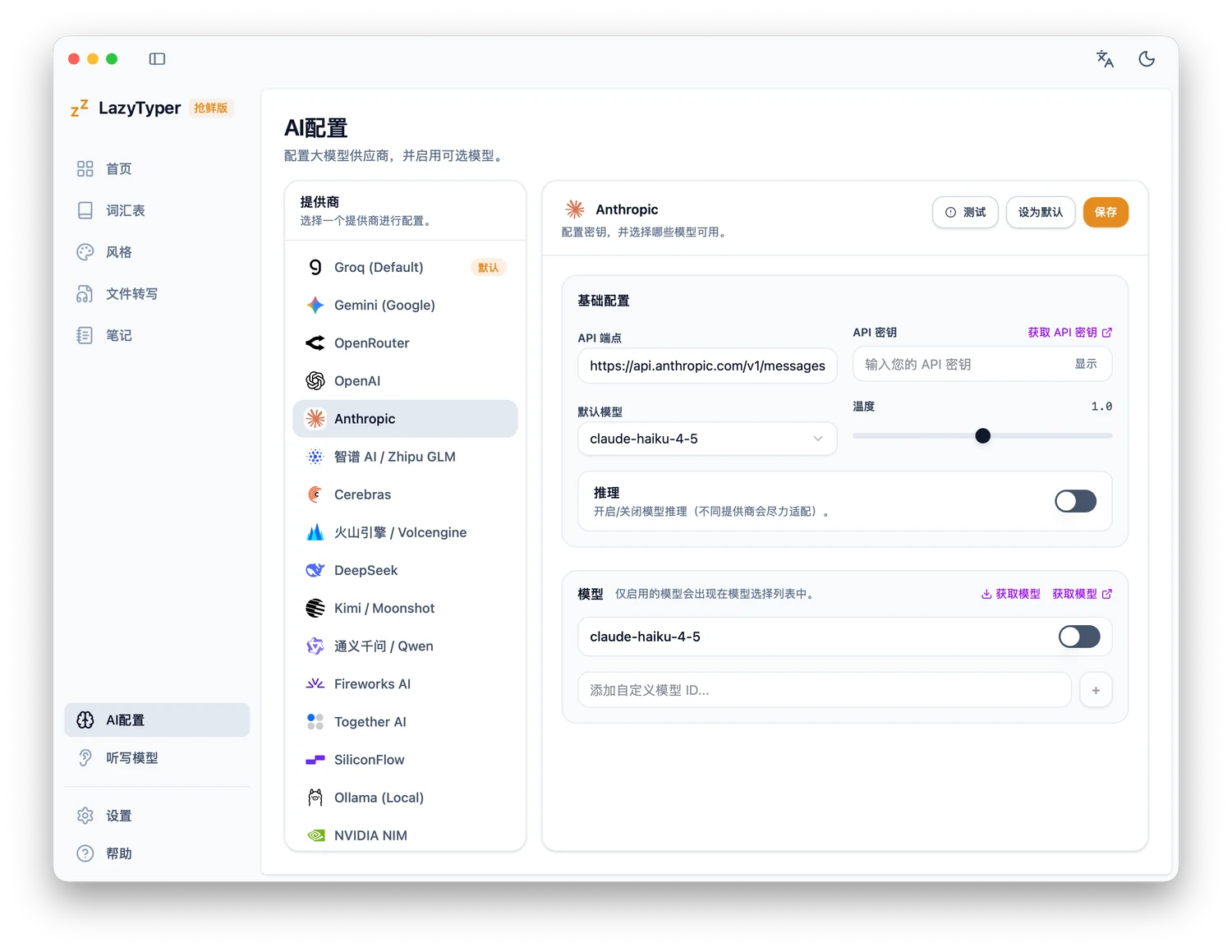
优势是你可以按场景 (当前使用的 App)定制输出风格(例如 Coding 场景输出格式化 Markdown、工作场景更正式、聊天更口语)可玩性很高。当然对应的缺点就是不像 Typeless 那么开箱即用,想调到顺手需要持续折腾。
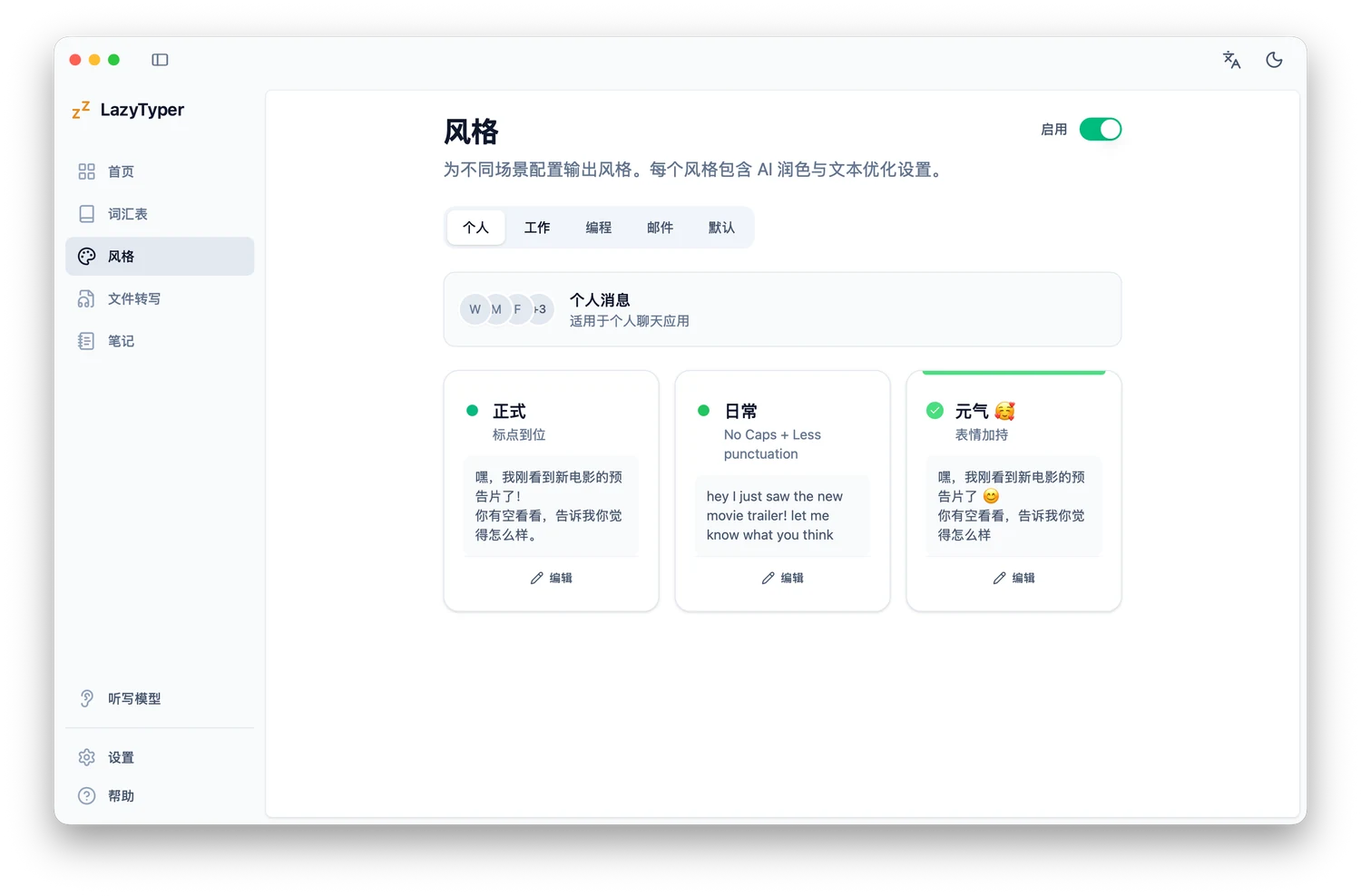
如果你非常在意“完全按自己的习惯输出”,LazyTyper 这类工具值得折腾。
PK 测试
一段特意加了一大堆语气词和口误的口播,看看各个软件的转写输出如何
红色高亮的是识别错误的,蓝色高亮的是故意说错纠正的
🤡
微信输入法:(评分从夯到拉,只能给到拉完了) 然后呢,就是那个叫比较也是比较火的那个闪电说,还有一个autoglm也就是那个智谱的那个输入法语音输入法。他们两个其实也是我觉得他是介乎它的可定义程度呢,就是介乎于Typeless以及那个lay type之间吧,就是像那个质谱书法呢,它是内置了那个语音模型服务了,就是你也是能直接用,然后它同时也能去配置各种,就是一些润色的PRO,就是也是能预设的,但是就是它只能接入自家的那个模型了,虽然它是免费提供的。然后呢,再往上可自定义化一点的就是那个智谱输入法了啊不是我是说闪电说了,它是能接入自己的那个API key, 你可以去接豆包大模型,你也可以去接其他的那些语音服务大模型,甚至于说,那个本地部署的模型离线模型都是可以的,这点就跟那个lazytyper是一样的。就是La type也是可以自定义的啊。然后,但是雷斯开普尔呢,它是可玩性就更高一点吧。其实都还好大差不差,我觉得这这些。就是他们都能去做一些自定义吧
🤨
豆包输入法: 然后呢就是那个比较火的那个闪电说,还有一个 AutoGLM,也就是那个智谱的那个书法,云书法。他们两个其实也是,我觉得它是介乎,它的可定义程度呢,就是介乎于 Tableau 以及那个 lacy type 之间吧。就是像那个智谱输入法呢,它是内置了那个语音模型服务了,就是你也是能直接用,然后它也能去配置各种,就是一些润色的 prompt,也就是能预设的。但是就是它只能接入自家的那个模型的,虽然它是免费提供的。然后呢,在网上可自定义化一些的,就是那个质朴输入法了。不是,我是说闪电说,它是能接入自己的那个 API key,你可以去接豆包大模型也可以去接其他的那些语音大模型服务,甚至于说那个本地部署的模型、离线模型都是可以的。这点就跟那个 Lazy Typer 是一样的,就是 Lacy Type 也是可以自定义的啊。然后但是 Lacy Type 呢,它是可玩性就更高一点吧。其实都还好,大差不差。我觉得这些就是他们都能做一些自定义吧。
🤔
闪电说(开启了“自动结构化”和“口语过滤”功能): 比较火的语音输入法有闪电说和 AutoGLM,也就是智谱的输入法。它们的可定义程度介于 TypeLess 和 LasyTaper 之间。 智谱输入法内置语音模型服务,可以直接使用,同时能配置润色点,修改预设设置。但它只能接入自家内置的模型,无法做修改,尽管提供免费服务。 闪电说更容易自定义,能接入自己提供的 API key,可以使用豆包大模型、其他语音服务大模型,甚至本地部署的离线模型。这一点与 Lasy Typist 相似,后者也支持自定义。 总体而言,这些工具都支持一定程度的自定义,Lazy Type 的可玩性更高一些,但差别不大。
👍
Typeless: 比较火的还有闪电说和 AutoGLM(也就是智谱的那个语音输入法)。 我觉得它们的可定义程度介乎于 Typeless 和 LazyTyper 之间:
- 智谱输入法 (a) 内置了语音模型服务,可以直接使用。 (b) 支持配置各种润色 Prompt,也可以修改预设。 (c) 缺点是只能接入自家的内置模型,虽然是免费提供的,但不能更改模型。
- 闪电说 (a) 自定义程度更高,支持接入你自己提供的 API Key。 (b) 可以接入豆包大模型,或者其他的语音服务大模型,甚至本地部署的离线模型都可以。 (c) 这点跟 LazyTyper 是一样的,都支持自定义。 相对来说,LazyTyper 的可玩性会更高一点。其实它们都大差不差,都能实现一定程度的自定义。
可以发现 Typeless 不仅识别成功率 100%,还结构化重新组织语言了
闪电说、LazyTyper 等软件理论上也能通过自定义润色 Prompt 调成这个效果,但是需要自己长期不断地调整
小结:差异主要在后处理
总的来说,我用过这么多款语音输入软件,最后还是用回了 Typeless。它确实比较省心,而且输出内容的质量很高。
我自己的感觉是:Typeless 的润色提示词(Prompt)应该是经过精心打磨的,它在各种场景下都能比较符合预期,不太会给你“惊吓”。比如:
-
当你想口语化表达时:它不会输出那种 AI 味很浓、过度严谨或过度结构化的东西
-
当你需要更正式的输出时(尤其是喂给 Coding Agent 出 Plan / 改代码):它的表达又会变得很专业
🍊
商业软件的价值与优势,很多时候就在这种“把脏活累活内化掉”的打磨上。
当然,如果你有非常强烈的个人偏好(比如你希望固定输出某种 Markdown 模板、或者你希望某些场景必须用你自己的术语体系),Typeless 可能无法 100% 满足你;这时更适合用 LazyTyper 这类高度自定义的工具,慢慢调出专属于你自己的润色提示词。
我也曾经尝试过自己调优,调了挺久,但最后还是不太满意,所以最终还是更倾向“省心优先”。
如果只看“识别对不对”,很多时候大家都能达到可用水平。(不过微信还是差点意思)。
尤其是像闪电说、LazyTyper 这种能接入豆包大模型的方案,豆包在中英文夹杂识别这块做得很准。
这些软件真正拉开差距的点,更多在“后处理”上(也就是把口语变成可用输入的那层工程):提示词工程和上下文工程
很多工具别看它们表面只是语音输入,其实背后做了不少 harness engineering,用长期/短期记忆、个人词典、知识库,用来让输出更贴近你
甚至于像 Typeless 最近新出的 1.0 版本,已经不满足于只做语音输入了,他想做你的电脑上的 AI 入口。
硬件怎么选:按“离嘴距离”和“延迟”排序
硬件这块我踩的坑,最后都能归结到两件事:
- 离嘴距离:麦离嘴越近,你就越能小声说,识别越稳(开放工位尤其重要)
- 延迟:不跟手会打断思维,还会吞掉你开头几个字
所以我更喜欢用一个很工程化的排序方式:优先选择“低延迟 + 近场”的输入源。
下面按“能用程度”从低到高聊聊(都能用,只是体验差异很明显)。
MacBook 内置麦:最简单,零成本开始
优点:
- 立刻开始,没有任何额外成本
缺点:
- 远场收音,你往往需要更大声
- 环境噪声/键盘声更容易混进来
适合:先验证自己是否喜欢“用说的跟 Agent 沟通”。
🤣
如果你是个社牛,这个方案已经完全足够了,周围的同事只会觉得你很 Pro

蓝牙耳机(例如 AirPods):比内置麦好,但别指望它能“悄悄话级别”
很多人第一反应是“我有 AirPods,直接用它的麦不就行了?”——它确实比电脑内置麦更近、更稳定一些,但我个人不太建议把它当主力收音设备。
主要是两个硬伤:
- 延迟问题:蓝牙耳机在 Mac 上启用麦克风的瞬间,经常会有 0.5~1 秒的启动延迟。你如果按下按键立刻开口,前面几个字很容易被吞。
- 距离问题:耳机麦在耳朵附近,离嘴还是有距离。你想小声说(尤其开放工位“压低音量”那种),识别准确率就会明显下降。这种“数据源不准”的问题,后面哪怕用 Typeless 这类整理软件,也很难完全救回来。
另外还有一个很具体的系统坑(至少我这边没找到解法):
- AirPods Pro + Mac:即使开了通透模式、也关掉了对话感知等功能,一旦 AirPods Pro 在 Mac 上开启麦克风,系统仍会出现一种“下意识压低环境音”的行为(很像自适应/降噪逻辑被强行触发),体感上非常难受,而且我没找到可靠的关闭方法。

或者带独立麦克风的头戴式耳机,收音效果好于 AirPods,但仍然存在延迟问题。
🧑🚀
戴上这个更像客服了 😁 用来 oncall 绝配
总结:蓝牙耳机“能用”,但很难做到稳定、低延迟、可小声的体验。
iPhone 连续互通
如果你不想在工位大声讲,iPhone 的「连续互通相机/麦克风」是个不错的方案:让 iPhone 做 Mac 的麦克风。
将 iPhone 通过数据线连接到 Mac,然后在系统设置 - 声音 里面就能找到这个输入设备。
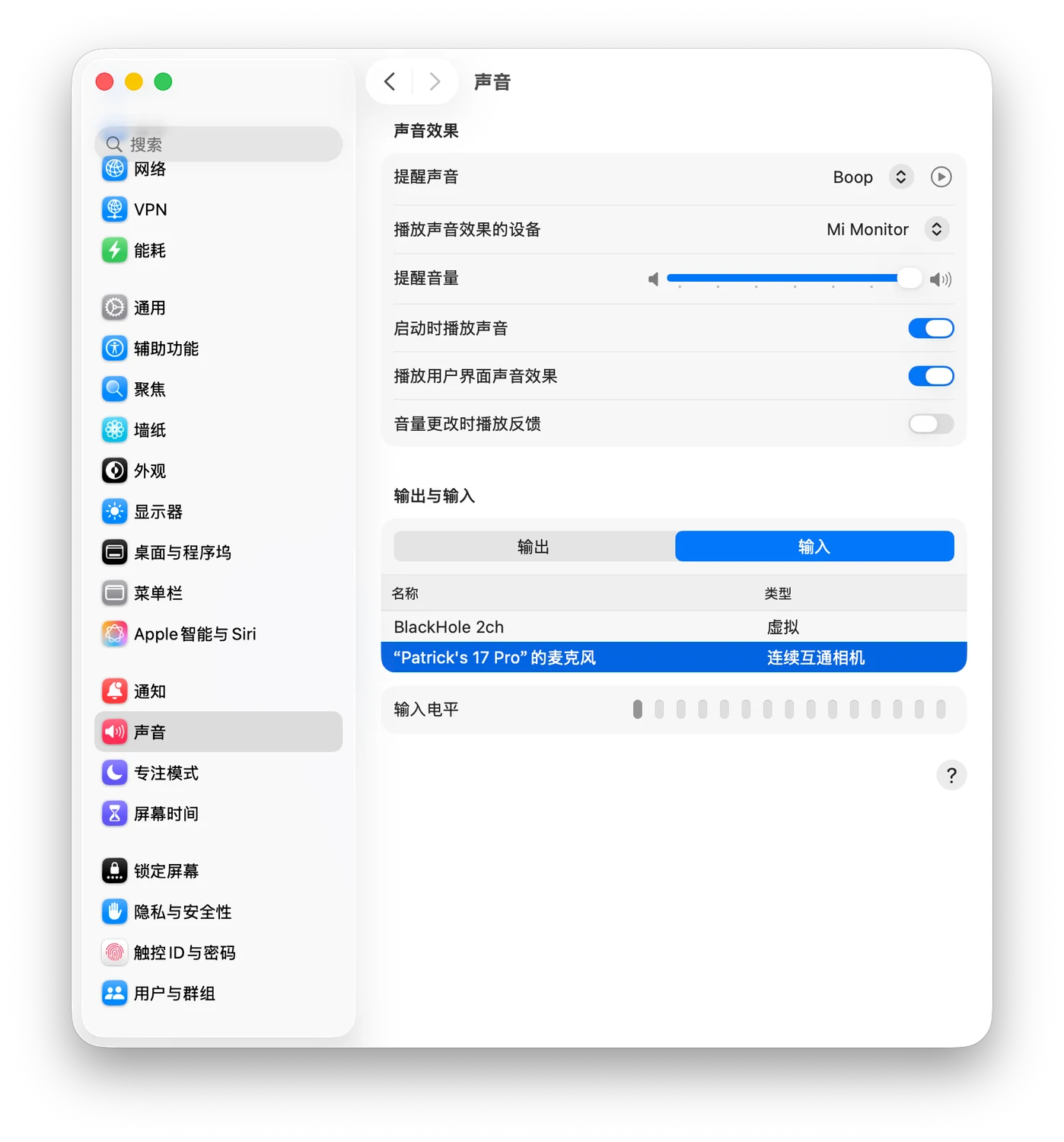
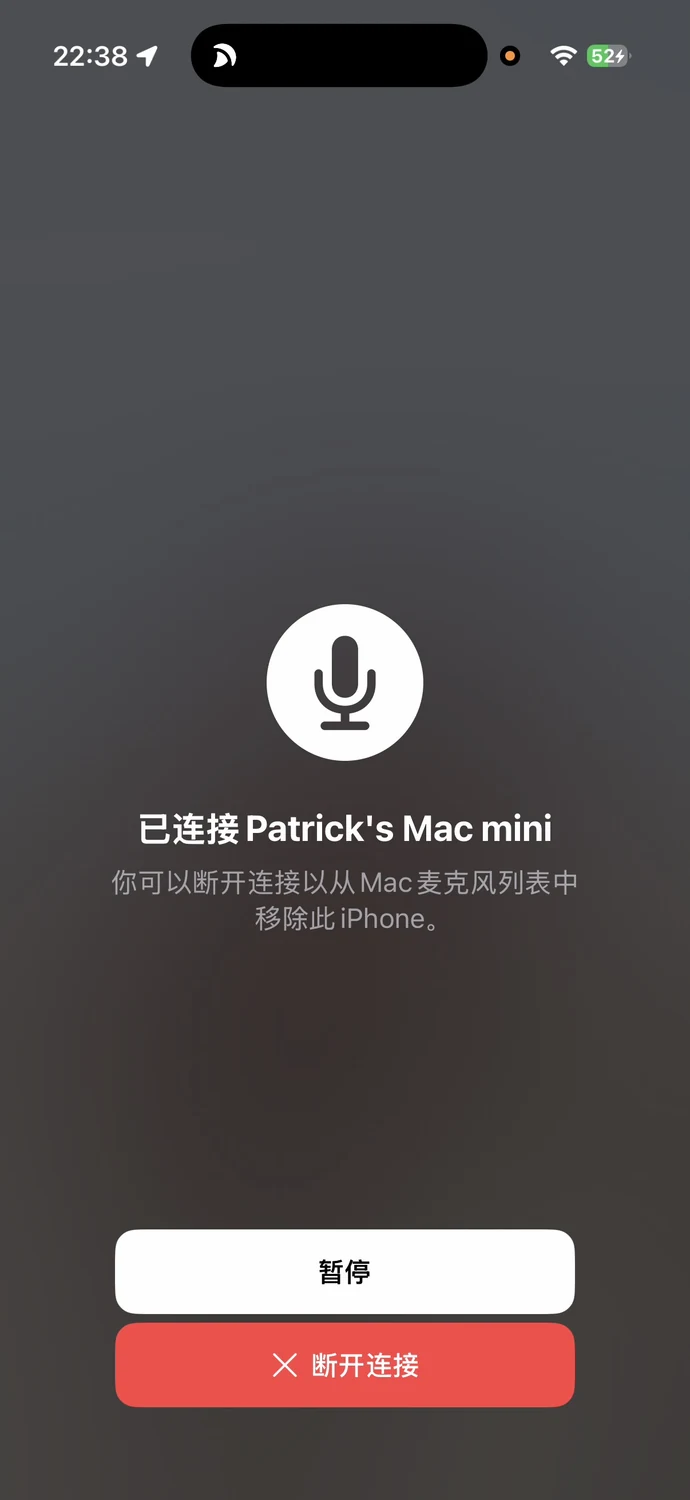
这里我强烈建议配一个桌面手机支架(磁吸/夹持都行):把手机架到更靠近嘴的位置,体验会比“手机躺桌上/离人远”好很多。(当然你把手机放在水瓶上支起来也不是不行)

但它仍然有两个现实问题:
- 小声说时准确率一般(悄悄话式音量会更明显掉准确率)
- 有延迟:按下录音到真正开始收音,可能要等 0.5~1 秒。Coding 这种高频短句交互里,这个延迟会让人有点烦。
总结:比蓝牙耳机更“可控”,但仍然不算特别跟手。
有线耳机(例如 EarPods)
它的优势是距离可控:你可以把麦克风拉到嘴边很近,小声说也更稳。
缺点是线缆束缚。

领夹麦克风
如果你准备把 Voice Coding 当成日常输入方式,我最推荐直接上 Type‑C 接收器的领夹麦(150~200 元档的入门级别就很够用了)比如 DJI Mic Mini、猛玛 LARK A1
为什么领夹麦体验最好:Type‑C 接收器插 Mac 上就是实时输入设备,延迟几乎可以忽略;声音更稳定,受环境影响更小。
提醒:下单要买一拖一(发射器+接收器),单发射器不能单独使用 🤣
这也是我目前一直使用的方案。
领夹麦的两种用法:
- 夹在领口:体验其实和“蓝牙耳机麦”在距离上有点像。你如果想特别小声说,准确率不一定稳。
- 桌面支架:用支架把领夹麦固定起来,离嘴只有一两厘米。这个体验会非常明显地变好:你基本可以“悄悄话”音量说话,识别仍然很准。


-
更新:摸索出了个新方案 🤓
- 支架还是太碍事了
- 用磁铁把麦克风吸附在蓝牙小键盘上
- 三个按键自定义为转写键、回车键和换行 (Shift+Enter)


桌面麦克风
桌面麦克风的收音效果非常好,还有定向收音效果。
只需要将麦克风的正面对准嘴巴,就能实现精准收音。
同时因为是有线连接,不用像领夹麦一样每天充电。
缺点就是非常贵,在 Voice Coding 场景下属于杀鸡用牛刀,如果你不是恰好家里有一个桌面麦的话🥸,不建议为了 Coding 而购买(入门级别的领夹麦已经非常够用了)

我常用的 Voice Coding 口播模板
我最常用的其实就是这种“够短,但信息不缺”的版本:
我在做【模块/功能】。目标是【要实现什么】。
约束是【不能动的点/必须兼容的点】。
你先复述你的理解和计划,我们对齐后再开始调研。
如果你有哪里不太明白的,向我采访和提问。
我很喜欢让 Agent 先复述,Agent 会把“理解偏差”尽早暴露出来,而不是等到代码已经改了一堆再返工。
另外一个技巧是让 Agent 采访你,一是能澄清细节,二是 Agent 能问出很多你没考虑过的边界情况。
👩🚀
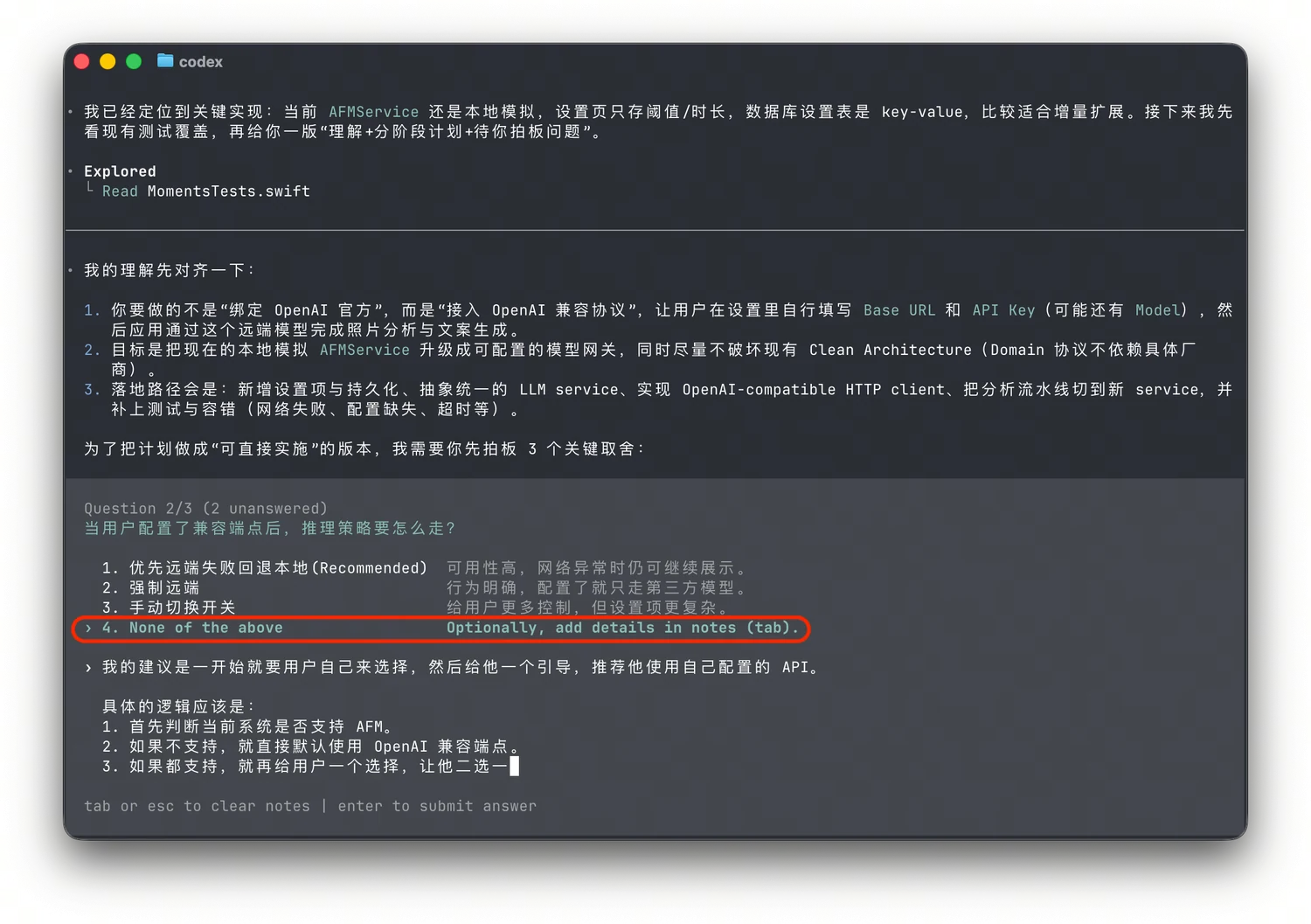
Tips Claude Code / Codex 等 Agent 经常会使用 AskUserQuestion 工具发送交互卡片让你单选或多选,此时即便里面有符合你预期的选项,我也建议你选 Other 选项然后语音给出更丰富的信息**。**
结尾
🤸♂️
这篇文章本身的主体部分也是我在外头吃饭逛街时跟我的 🦞 用 Typeless 聊了四个来回聊出来的。回看了一下聊天记录,每一轮我都给 🦞 输入了大量上下文,我感觉如果按以前打字聊天的方式,可能要聊上个十几二十轮才行。



对我来说,Voice Coding 的价值不是“少打字”,更重要的是:
- 我更愿意把关键约束讲完整
- Agent 更容易形成正确的任务模型
- 我少了很多“啊这个我刚才没说清”的返工
如果你已经在用 Claude Code 这类 Coding Agent,找一个你这周本来就要做的小任务,换成语音输入试一次就明白了。
不需要换一整套工作流,也不需要追求全程语音。你只要体验一下“把上下文一次讲清楚”的感觉,立马就能爽到😋,同时也能明白它为什么有用。