杂谈网络协议之种子与P2P
最近学了些P2P协议相关的内容,做了些笔记。
P2P
P2P 即 peer-to-peer,为了解决 HTTP 或 FTP 下载文件时难以解决单一服务器带宽压力的缺点。P2P 的特点是资源开始并不集中地存储在某些设备上,而是分散地存储在多台设备上,而是分散地存储在多台设备上。这些设备我们姑且称为 peer。
想要下载一个文件的时候,只需得到那些已经存在了文件的 peer,并和这些 peer 之间,建立点对点的连接,而不需要到中心服务器上,就可以就近下载文件。一旦下载了文件,你也就成为 peer 中的一员,你旁边的那些机器,也可能会选择从你这里下载文件,所以当你使用 P2P 软件的时候,例如 BitTorrent,往往能够看到,既有下载流量,也有上传的流量,也即你自己也加入了这个 P2P 的网络,自己从别人那里下载,同时也提供给其他人下载。
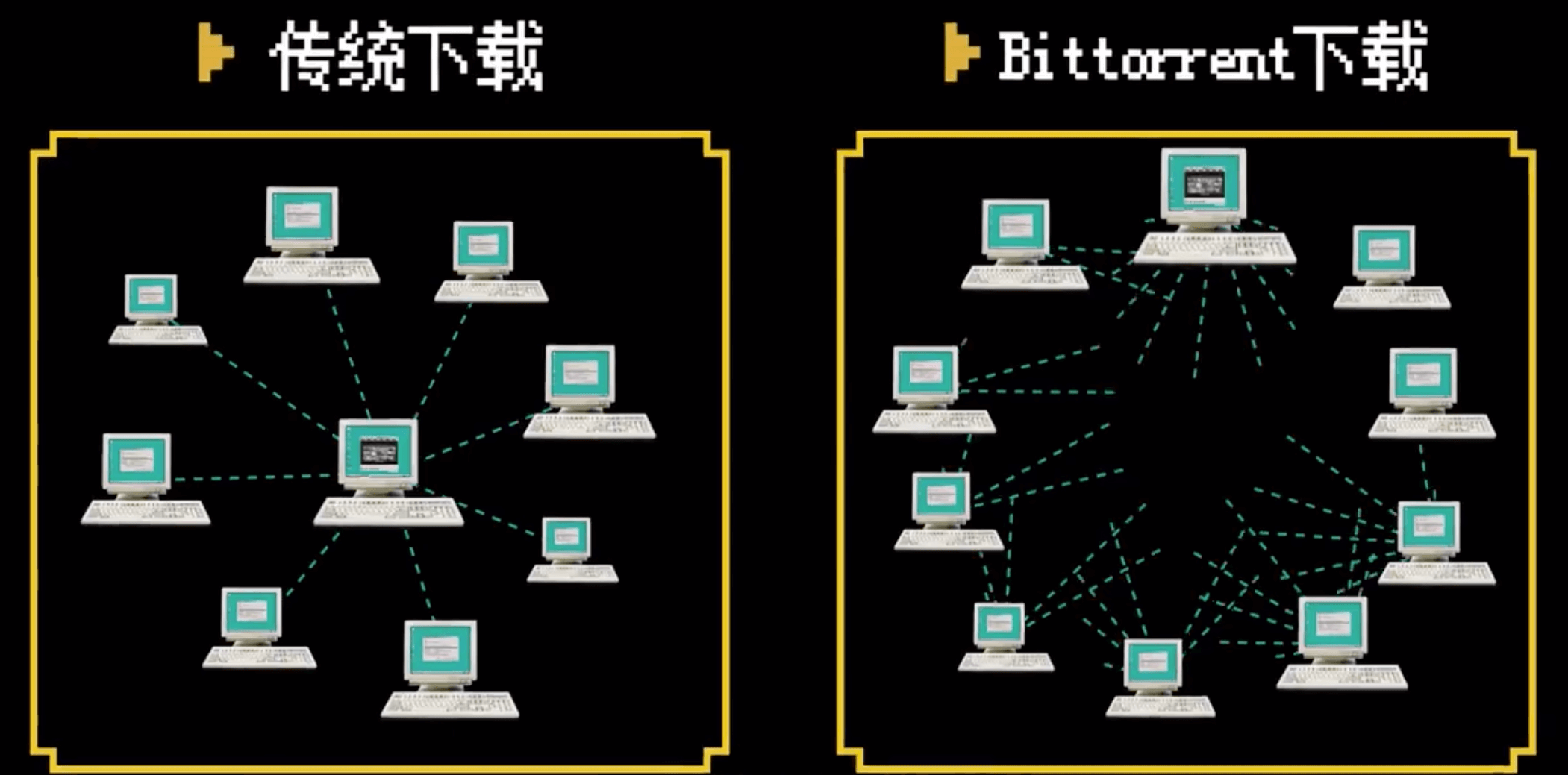
美国工程师 Bram Cohen 在 2001 年发布了 BitTorrent 协议,资源不再由一个人或一个中心服务器提供,而是所有人提供给所有人,下载的人越多,速度越快。
BitTorrent 的核心思想是把文件分成很多个小块,让下载者互相连接。协议需要资源共享者生成一个包含下载信息的种子文件,后缀是 .torrent,即 BT 种子。
torrent
.torrent 种子文件由两部分组成,分别是:announce(tracker URL)和文件信息
文件信息包含文件的名字、大小,分块后每块文件的大小、哈希值等,具体如下:
- info 区:指定的是种子文件数量、文件大小、目录结构、目录和文件的名字
- Name 字段:指定顶层目录名字。
- 每个段的大小:BitTorrent 协议把文件分成很多个小段
- 段哈希值:整个种子中,每个段的 SHA-1 哈希值拼在一起
下载时,BT 客户端首先解析.torrent 文件,得到 Tracker 地址,然后连接 Tracker 服务器。
Tracker 很重要,通过 Tracker 我们才能找到其他下载者的联系方式。当你用下载软件打开种子,就会开始联系种子文件里内置的 Tracker 服务器,告诉 Tracker 我要下载这个文件,服务器会记录下你的 IP,并把其他正在下载或下载完成的人的 IP 返回给你,这样你们就可以愉快的组队下载了。
Tracker 服务器回应下载者请求,将其他下载者包括发布者的 IP 提供给下载者。下载者再连接其他下载者,根据种子文件,双方互相告知自己已经有的块,然后交换对方没有的数据。此时不需要其他服务器参与,并分散了单个线路上的数据流量,减轻服务器负担。
下载者每得到一个块,需要算出下载块的 Hash 验证码,并与.torrent 文件中的对比。如果一样,则说明块正确,不一样则需要重新下载这个块。这种规定是为了解决下载内容的准确性问题。
当然,如果没有找到正在下载的人,资源发布者也不在线,你就只能以 0kb/s 的速度等着了。
不难发现,Tracker 服务器是 P2P 网络的弱点,如果 Tracker 被关闭或封禁,你就无法找到同伴,也难以完成下载,BT 依然是中心化的协议。
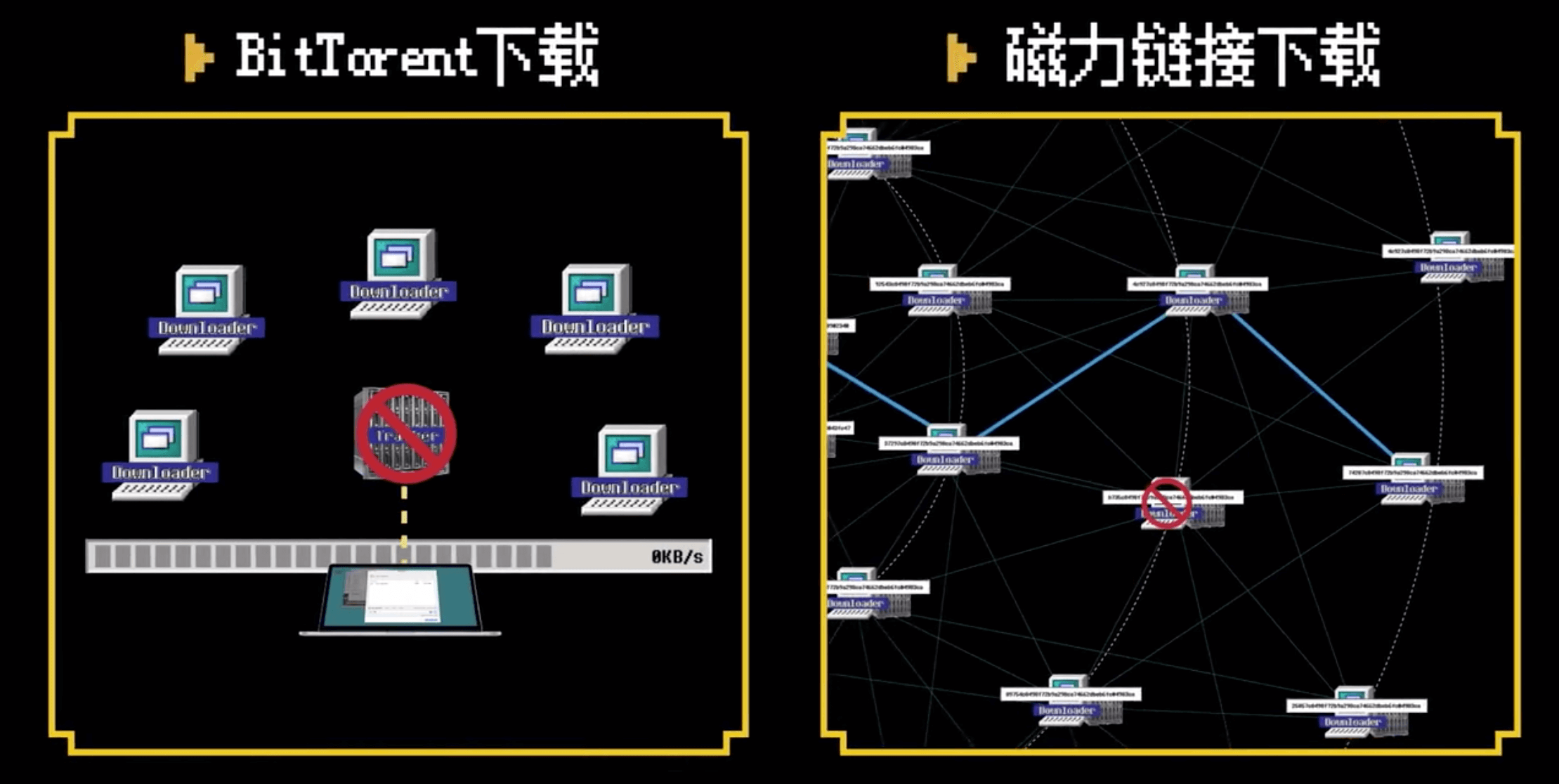
DHT 去中心化网络
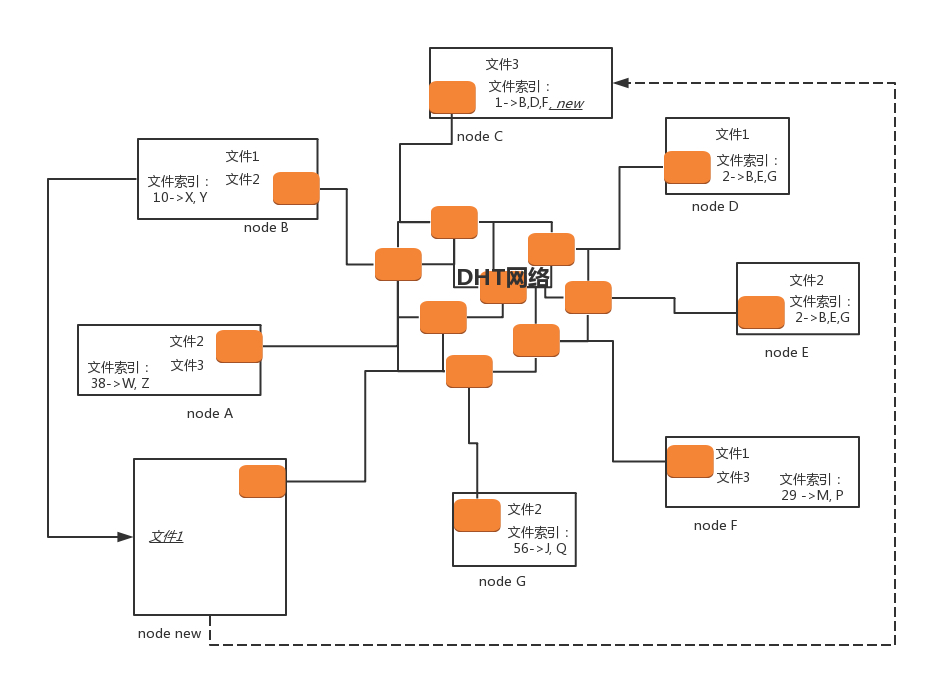
为了摆脱对 Tracker 服务器的依赖,彻底去中心化,于是产生了一种叫做 DHT(Distributed Hash Table)的去中心化网络,每个加入 DHT 网络的人,都要负责存储这个网络里的资源信息和其他成员的联系信息,相当于所有人一起构成了一个庞大的分布式存储数据库。
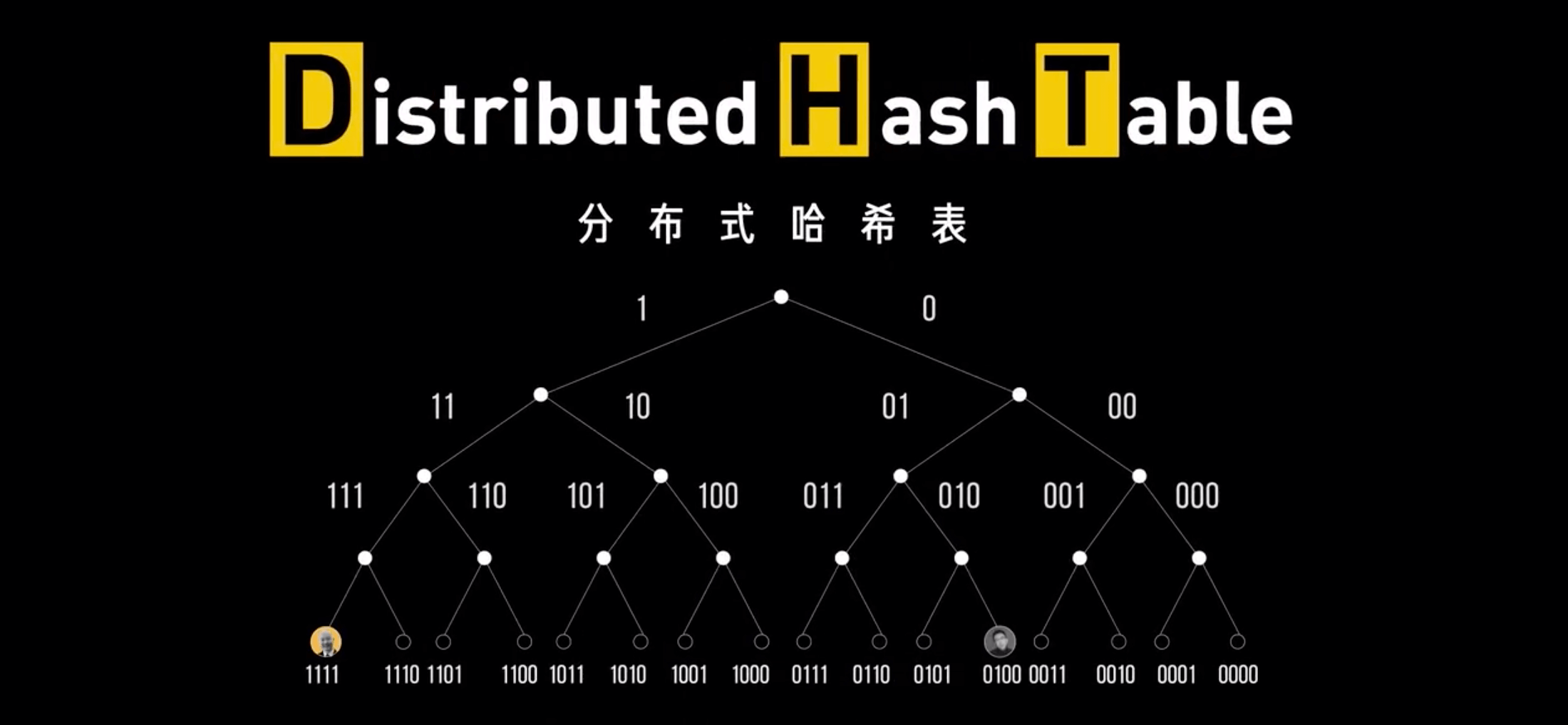
DHT 的本质是把所有人都变成一个小型 Tracker,每个人都拿着一份动态更新的地址和文件信息。我找与我连接的 10 个人,他们再各自找 10 个人,一传十十传百、千、万,最后我通过N个人的中转,找到应该连上的人。
有一种著名的 DHT 协议:Kademlia。任何一个 BitTorrent 启动之后,它都有两个角色。一个是 peer,监听一个 TCP 端口,用来上传和下载文件,这个角色表明,我这里有某个文件。另一个角色 DHT node,监听一个 UDP 的端口,通过这个角色,这个节点加入了一个 DHT 的网络。
在 DHT 网络中,每个 DHT node 都有一个很长的 ID 字符串。每个 DHT node 都有责任掌握一些知识,即文件索引,即它应该知道某些文件是保存在哪些节点上。它只需要有这些知识就行,自己本身不一定就是保存这个文件的节点。node 应该知道哪些知识是通过哈希算法计算出来。
每个文件都有一串通过 SHA1 哈希算法计算出唯一的文件 ID,可以产生 2 的 (4*40) 即 2 的 160 次方种组合,用只有 0 和 1 的二进制表示就是 160 个 0 和 1。
而每个节点也有一串 160 位的 0 和 1,作为节点 ID。根据这 160 位数,我们可以计算节点和节点之间,节点和资源之间的距离。
在 Kademlia 网络中,距离是通过异或(XOR)计算的。以5位举例,01010 与 01000 的距离,就是两个 ID 之间的异或值,为 00010,也即为 2。 01010 与 00010 的距离为 01000,也即为 8。01010 与 00011 的距离为 01001,也即 8+1=9。以此类推,高位不同的,表示距离更远一些;低位不同的,表示距离更近一些,总的距离为所有的不同的位的距离之和。
有个理论是,社交网络中,任何两个人直接的距离不超过六度,也即你想联系比尔盖茨,也就六个人就能够联系到了。
假设小明发布了一个文件,就能计算他所知道的节点 ID 与这个文件 ID 的距离,让算出来最距离最短的节点再计算它知道的节点和文件 ID 的距离,重复这个过程,就能找到与文件 ID 的距离最短的一批节点 ID,把小明提供的下载信息存在这里。
这样,下载者也只要找到和文件 ID 距离接近的节点 ID,就能建立连接,开始下载。
DHT 网络如何维护
就像人一样,虽然我们常联系人的只有少数,但是朋友圈里肯定是远近都有。DHT 网络的朋友圈也是一样,远近都有,并且按距离分层。
假设某个节点的 ID 为 01010,如果一个节点的 ID,前面所有位数都与它相同,只有最后 1 位不同。这样的节点只有 1 个,为 01011。与基础节点的异或值为 00001,即距离为 1;对于 01010 而言,这样的节点归为“k-bucket 1”。
如果一个节点的 ID,前面所有位数都相同,从倒数第 2 位开始不同,这样的节点只有 2 个,即 01000 和 01001,与基础节点的异或值为 00010 和 00011,即距离范围为 2 和 3;对于 01010 而言,这样的节点归为“k-bucket 2”。
如果一个节点的 ID,前面所有位数相同,从倒数第 i 位开始不同,这样的节点只有 2^(i-1) 个,与基础节点的距离范围为 [2^(i-1), 2^i);对于 01010 而言,这样的节点归为“k-bucket i”。
最终到从倒数 160 位就开始都不同。差距越大,陌生人越多,但是朋友圈不能都放下,所以每一层都只放 K 个,这是参数可以配置。
DHT 网络节点的查找
假设,node A 的 ID 为 00110,要找 node B ID 为 10000,异或距离为 10110,距离范围在 [2^4, 2^5),所以这个目标节点可能在“k-bucket 5”中,这就说明 B 的 ID 与 A 的 ID 从第 5 位开始不同,所以 B 可能在“k-bucket 5”中。
然后,A 看看自己的 k-bucket 5 有没有 B。如果有就找到了;如果没有,在 k-bucket 5 里随便找一个 C。因为是二进制,C、B 都和 A 的第 5 位不同,那么 C 的 ID 第 5 位肯定与 B 相同,即它与 B 的距离会小于 2^4,相当于比A、B 之间的距离缩短了一半以上。
再请求 C,在它自己的通讯录里,按同样的查找方式找一下 B。如果 C 知道 B,就告诉 A;如果 C 也不知道 B,那 C 按同样的搜索方法,可以在自己的通讯录里找到一个离 B 更近的 D 朋友(D、B 之间距离小于 2^3),把 D 推荐给 A,A 请求 D 进行下一步查找。
Kademlia 的这种查询机制,是通过折半查找的方式来收缩范围,对于总的节点数目为 N,最多只需要查询 log2(N) 次,就能够找到。
DHT 网络节点之间的沟通
Kademlia 算法中,每个节点只有 4 个指令。
- PING:测试一个节点是否在线。
- STORE:要求一个节点存储一份数据。
- FIND_NODE:根据节点 ID 查找一个节点
- FIND_VALUE:根据 KEY 查找一个数据,与 FIND_NODE 类似
DHT 网络的更新
每个 bucket 里的节点,都按最后一次接触的时间倒序排列,这就相当于,朋友圈里面最近联系过的人往往是最熟的。
每次执行四个指令中的任意一个都会触发更新。
当一个节点与自己接触时,检查它是否已经在 k-bucket 中,也就是说是否已经在朋友圈。如果在,那么将它挪到 k-bucket 列表的最底,也就是最新的位置,刚联系过,就置顶一下,方便以后多联系;如果不在,新的联系人要不要加到通讯录里面呢?假设通讯录已满的情况,PING 一下列表最上面,也即最旧的一个节点。如果 PING 通了,将旧节点挪到列表最底,并丢弃新节点,老朋友还是留一下;如果 PING 不通,删除旧节点,并将新节点加入列表,这人联系不上了,删了吧。
这个机制保证了任意节点加入和离开都不影响整体网络。
磁力链接
今天最流行的下载方式是磁力链接(Magnet URI scheme)就是基于 DHT 网络的,通常是一串这样的神秘代码:

前面都是标准格式,最重要的是这 40 个 16 进制的数字即 160 位 2 进制数字。任何文件丢进 SHA1 哈希算法都能得到一串这样字符,40 位、16 进制、只属于这个文件,它能帮我们找到我们要下载的东西。
根据上面讲的 DHT,只需要一串文件 ID 和存储在本地的 K 桶数据,你就可以高效的找到要下载的文件。而资源的发布者和传播者也只需要分享 40 个数字就好,足够简单,方便和隐私。
在真实的 DHT 网络,每个 K 桶至少记录了 8 个节点,任何一个节点下线,都不会影响整个网络的运行。
作为文件和节点 ID ,2 的 160 次方也足够大,大到全地球 70 亿人每秒下载 10000 个种子,也足够下载百万亿年直到宇宙终结。
这些天才们的设计,让我们拥有了一个无法被审查和追踪的去中心化网络。这催生了庞大的盗版产业,但也让很多内容有机会避开审查。
因为网站可以被隔离、被拔线、被禁止访问,但种子不会。只要种子不死,那些不存在的音乐图书和视频就还活在互联网上,没有任何人可以毁掉。
小结
-
下载一个文件可以使用 HTTP 或 FTP,这两种都是集中下的方式,而 P2P 则换了一种思路,采取非中心化下载的方式;
-
P2P 也是有两种,一种是依赖于 tracker 的,也即元数据集中,文件数据分散;另一种是基于分布式的哈希算法,元数据和文件数据全部分散。